I - Architectures as priors on function space, initializations as random nonlinear projections
Change of design paradigm
classical ML : design features by hand, vs. deep learning : meta-design of features : design architectures that are likely to produce features similar to the ones you would have designed by hand
an architecture = a parameterized family (by the neural network's weights)
still a similar optimization problem (find the best parameterized function), just, in a much wider space (many more parameters)
Architecture = prior on the function
prior :
as a constraint: what is expressible or not with this architecture?
but most networks already have huge capacity (expression power) $ \implies $ expressivity = most often not useful
$ \implies $ probabilistic prior: what is easy to reach or not?
good architecture : with random weights, already good features (or not far) [random = according to some law, see later]
in classical ML, lots of works on random features + SVM on top (usually from a kernel point of view); random projections
learn only a fraction of the features of each layer = sufficient to get good results (not very surprising)
if one can learn only one layer, choose the middle one
if you use random features: batch-norm is important (of course: the features should be "normalized" somehow at some point instead of making the function explode or vanish; cf next section)
bias of the architecture (i.e. proba on possible functions to learn):
Random initialization: random but according to a chosen law that induces good functional properties
avoid exploding or vanishing gradient (e.g.: activities globally multiplied by a constant factor $\gamma$ > 1 or < 1 at each layer: would obtain a factor $\gamma^L \gg 1$ or $\ll 1$ after $L$ layers)
multiplicative weights: uniform over $ \left[- \frac{1}{\sqrt d}, + \frac{1}{\sqrt d} \right] $, or Gaussian $ \mathcal{N}(0, \sigma^2 = \frac{1}{d}) $ where $d$ = number of inputs of the neuron
justification: if weights $w_i$ are i.i.d. of mean 0 and standard deviation $\frac{1}{\sqrt{d}}$ and inputs $x_i$ are i.i.d. of mean 0 and variance 1, the neuron will compute $\sum_i w_i x_i$, which will still be of mean $\E_x \E_w \sum_i w_i x_i = \E_w \sum_i w_i \times 0 = 0$ and of variance $\E_x \E_w \sum_i w_i^2 x_i^2 = \sum_i \E_w w_i^2 \E_x x_i^2 = \sum_{i=1}^d \frac{1}{d} \times 1 = 1$. Thus, the output of the neuron will follow the same law as its inputs (mean 0, variance 1). And consequently, if one stacks several such layers, the output of the network will still be of mean 0 and variance 1.
multiply by an activation-function-dependent factor if needed (eg: ReLU divides variance by 2, since it is 0 over half of the input domain; so, correct by $\times \sqrt 2$)
previous paragraph: ensures that, at initialization, $f(x)$ is in a reasonable range (notations: $x$ = input, $f$ = function computed by the neural network)
here: check also the Jacobian $\frac{df}{dx}$ at initialization
turns out that, with $n_l$ = "number of neurons in layer $l$":
variance$\left(\frac{df}{dx}\right)$ is fixed: $\frac{1}{n_0}$
var$\left( \left(\frac{df}{dx}\right)^2\right)$ , i.e. the fourth moment $\E\left[ \left(\frac{df}{dx}\right)^4 \right]$ is lower- and upper- bounded by terms in $e^{\sum_{\mathrm{layers} \, l} \; \frac{1}{n_l}}$
$ \implies $ $\sum \frac{1}{n_l}$ is an important quantity
$ \implies $ avoid many thin layers; if on a neuron budget, choose equal size for all layers
Designing architectures easy to train
training "deep" networks : actually not really deep in terms of distance between any weight to tune and the loss information (in number of neurons to cross in the computational graph), for easier information communication (through the backpropagation)
either proper choice of activation function (e.g.: SELU), meant to keep constant activity variance from layer to layer
or add scaling layers so as to learn global scalings easily (instead of moving each parameter independently): layer-norm, instance-norm, batch-norm (more debatable but working in practice), etc., fixup initialization...
we saw that overparameterized networks (i.e. large layers) seem to be easier to train
$ \implies $ "good architecture" is about "more likely to get the right function"; better, future optimizers might make smaller architectures more attractive
II - Architectures
NB: this is about current most popular architectures, not to be taken as an exhaustive, immutable list
$ \implies $ "deep learning" is moving towards general "differentiable programming", with more flexible architectures/approaches every year: any computational graph provided all operations are differentiable.
CNN : reducing parameters by sharing local filters + hierarchical model ($ \implies $ invariance to translation, + much greater generalization power [cf Chapter 1])
needs to be interleaved with "zooming-out" operations (such as max-poolings) to be able to get wide enough receptive field (otherwise, won't see the whole object)
typical conv block: conv ReLU conv ReLU max-pool with conv 3x3 or so
NB: do not use large filters: better rewrite 15x15 as a hierarchical series of 3x3 filters: though the expressivity is similar, the probabilities are different, e.g. typical Fourier spectrum is different
Auto-encoder, VAE, GAN : (cf later chapter about generative models)
adversarial approach $ \implies $ no need to model the task anymore:
The generated image will be a good face if...
... it has two eyes, of such color, size, one nose, etc.
vs.
... if the discriminator doesn't make the difference with real data.
basic RNN : $h_{t+1} = f( h_t, x_t )\;\;$ (notations: $x_t$ = input at time $t$, $\;\;h_t$ = internal state at time $t$)
issue: memory? (keep a description of the context: here $h_t$ is completely lost at time $t+1$!)
get "leaky": progressive update of the memory: $h_{t+1} = h_t + f(h_t, x_t)$
get "gated": i.e. make the update amount dependent on the context (cf "attention" later) : $h_{t+1} = \alpha h_t + (1-\alpha) f(h_t, x_t)$ with $\alpha = g(h_t, x_t) \in [0,1]$ (named forget gate)
NB: a bit more complex that the formula above. Two hidden streams: $c_t$ and $h_t$. The real memory stream is $c_t$ (named $h_t$ in our formula), while $h_t$ is an auxiliary stream used to compute $\alpha$ and the update (in $g$ and $f$ above respectively). Also, $\alpha$ and $1-\alpha$ are decoupled and not required to sum up to 1.
design of the "forget gate" justified by continuous analysis, with additional recommendations on bias initialization (equivalent to typical memory duration) as $b \sim -\log\left( \mathrm{Uniform}\left[1, T_\max\right] \right)$ where $T_\max$ is the maximum expected memory duration [Can recurrent neural networks warp time? Corentin Tallec, Yann Ollivier, ICLR 2018]
Dealing with scale & resolution
Classification/generation of high-resolution images: pyramidal approaches (e.g. any conventional conv-network for ImageNet / reverse pyramid for image generation)
for classification (ImageNet): e.g. LeNet, AlexNet, VGG... : general shape = pyramid : fine to coarse resolutions
each block is of the form $h_{l+1} = h_l + g(h_l)$ instead of $h_{l+1} = g(h_l)$
NB: each block = 2x conv-ReLU
philosophy: each block adds to the previous ones, i.e. add fine corrections to what previous block did
advantage: the output is of the form $f = \sum_l h_l$, so for any layer $l$, $\;\frac{d \mathrm{Loss}(f)}{d h_l} = \frac{\partial \mathrm{Loss}(f)}{\partial h_l} + \frac{\partial \mathrm{Loss}(f)}{\partial h_{l+1}} \frac{d h_{l+1}}{dh_l} + \dots $, so that there's a direct feedback to each layer, which helps optimization, especially at the beginning of the training.
or chain of blocks initialized to Identity (Highway network; not as common in the literature)
same as ResNet but with attention modules instead of additions (like LSTM, but non stationary) : $\alpha\, \mathrm{old} + (1-\alpha) \mathrm{new} $ with adaptive $\alpha$
using orthogonal matrices (for initialization) in such a way that no explosion/vanishing can happen
yet, validated on easy tasks only (MNIST, CIFAR 10); notice performance saturation with depth, and argue that architecture design = important, not just depth.
chain of blocks, each of which = parallel blocks whose outputs are concatenated (later turned in a ResNet form)
philosophy: hesitation in the design? shall we use 3x3 or 4x4 conv in this block? Well, try all possibilities in parallel, and let the training handle and pick what is useful.
auxiliary losses at intermediate blocks to help training (same idea: to give better information from a loss backpropagation to early layers as well)
series of blocks, each of them = feed-forward network of a few layers with dense connections between layers (i.e. each layer receives information from all previous ones in its block)
philosophy: not plain straight-forward neural network, but mix of information at different levels; hesitation in the design? let the network handle and pick the connections that are useful
as in particular within each block the two extreme layers are directly connected, the shortest path for the backpropagation to reach any layer is short (blocks are fast to go through)
Examples (case study)
What architecture would you propose for:
Video analysis/prediction
auto-encoder + LSTM = conv-LSTM
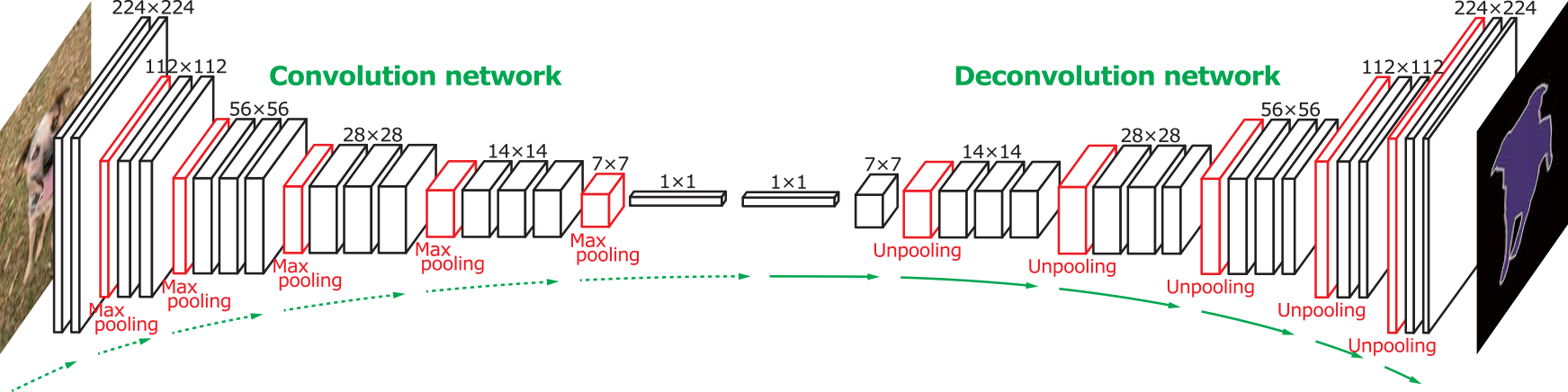
Aligning satellite RGB pictures with cadaster maps (binary masks indicating buildings, roads, etc.: one label per pixel), i.e. estimating the (spatial) non-rigid deformation between the two images
full resolution output required (2D vector field), multi-scale processing $\implies$ very deep network to train
Attention mechanisms: from basics to Transformers and beyond
Basics of attention:
possible goals:
transistor: transfer one variable ($a$) or another one ($b$) depending on the context (switching variable $\alpha$)
combine two variables $a$ and $b$ by summing them, but with weights $(\alpha, 1-\alpha)$ that depend on some context $c$
examples of context: $a$ and $b$ themselves, or other features produced by the neurons/layers that produced $a$ and $b$
how:
given two real variables $a$ and $b$ (or vectors of same dimension, actually)
create a a weighting variable $\alpha \in [0,1]$ (e.g. with a softmax) that depends on some context $c$
return $\alpha a + (1-\alpha) b$ with $\alpha = \alpha(c)$
→ cf MinimalRNN/LSTM where it is used to control the amount of update/forget at each step
want to combine 'values' $V_i$, each of which is introduced with a 'key' $K_i \in \R^d$ (thought of as a descriptor of the context);
the way to combine these values depend on the mood of the operator and on how it likes the various 'keys';
i.e. given a 'query' $Q \in \R^d$, one will search for the most suitable 'keys', i.e. the $K_i$ most similar to $Q$, and combine the associated 'values' $V_i$ accordingly:
return $\sum_i w_i V_i$ with weights $w_i$ that somehow depend on the similarity between $Q$ and $K_i$, which will be quantified as the inner product $(Q \cdot K_i)$.
example in NLP: translation of a sentence to a different language: at every step, each word has a certain number of features to describe it; how to incorporate information from other words? All words should not influence every other word, but influence should be selective (close semantic, or close grammatical relationship [subject/verb], etc.). Each word in turn will be the query $Q$, while all other words are the (value $V_i$, key $K_i$) pairs.
attention block: function(query $Q$, keys $(K_i)$, values $(V_i)$):
Q $\mapsto \sum_i w_i V_i $
with $\sum_i w_i = 1$ : softmax of the similarities $(Q \cdot K_i)$
i.e. pick values of similar keys (similarity being defined as correlation in $\R^d$)
more exactly: normalize $(Q \cdot K_i)$ by $\sqrt{d}$ before applying softmax, where d = length(query) = length(key), for better initialization/training, as $(Q \cdot K_i)$ is expected to be of the order of magnitude of $\sqrt{d}$ (same spirit as Xavier Glorot's initialization)
NB: 'values' $V_i$ can be real values, but you can consider also vectors in $\R^p$...
"multi-head" block : apply several attention modules (with different keys) in parallel, and concatenate their outputs $\implies$ allow to assemble different parts of the 'value' vectors
"Encoder"/"decoder": names for historical reasons, not related anymore to the architecture itself but to the training method: masked generation, vs. auto-regressive attention (cf self-supervision later)
Variations on Transformers with linear complexity in number of tokens (instead of quadratic)
Issue: quadratic cost in the number of tokens $\implies$ heavy. Alternatives:
scaling laws: how performance evolves with dataset size, model size, and training time. Useful to know how to scale up properly (e.g., it is useless to increase dataset size if the bottleneck is not there).
High Performance Computing (HPC) aspects : the examples of Mixtral and DeepSeek
"open source" ? not really: model weights are available, but not the training database
the MLP after the self-attention is a mixture of experts (MoE) (many MLPs in parallel, specialized in different contexts):
don't use all MLP heads in parallel each time but only relevant ones (to decrease computational cost)
the experts that are chosen depend on the token
possibly, also include some shared ones always used
DeepSeek-R1 obtained based on DeepSeek-V3, the same way chatGPT (3.5) is obtained from GPT-3
RL : generate candidate solution to a problem, evaluate it (is the maths reasoning correct? the answer correct?) $\implies$ reward.
and fine-tuning on examples of desired answers
Change of paradigm: fine-tuning without training parameters (no gradient descent)
Prompting alters significantly the output
In-Context Learning ICL :
art of prompting the LLM to make it solve a task it has never been trained on before
can learn from a dataset given by prompt without tuning parameters : attention enables this (weights change as a function of the context)
What is "learning" nowadays ?
Building systems on top of neural networks
Chain of thoughts: how to make an LLMs explain its outputs or its reasoning? just by prompting it to do so...
RAG (Retrieval-Augmented Generation)
retrieve documents that seem related
include them via a prompt
Agentic AI
pipeline of prompts (the same way one breaks a task into sub-parts)
= combining several LLMs seen as agents with assigned roles (i.e. prompts), interacting with each other (e.g., A writes the code, B checks it, C makes an experiment with it, D writes the report)
absolute positional embedding (of tokens) = not sufficient $\implies$ relative or rotary encodings (RoPE) are better!
BERT << GPT : « It is expected that encoder-based models do not learn very deep NT (non-terminal symbols) information, because in a masked-language modeling (MLM) task, the model only needs to figure out the missing token from its surrounding, say, 20 tokens. This can be done by pattern matching, as opposed to a global planning process like dynamic programming.»
probing: train a linear predictor to see whether the states of the network encode the nodes of the CFG tree (they do)
$\implies$ these LLMs actually compute a kind of dynamic programming algorithm
include mistakes in the training data for better results! but at the right level (grammar mistakes)
Part 3:
train with each information shown several times, written in different ways $\implies$ forces to distinguish format vs content, instead of learning "by heart"
show samples 100 times = not sufficient ; 1000 times sufficient : to store all information shown
Other applications of attention mechanisms: Squeeze, R-CNN
attention on features of a CNN / blocks in an Inception / features in a ResNet block / etc.
principle: each block produces many features; let's focus on the features that seem to be important for our particular input image.
for this: multiply all activities at the output of a block by a feature-dependent factor, in a way that depends on the current context (all block activities, summarized [i.e. averaged over all pixel locations]).
R-CNN : Region-CNN
papers: R-CNN, Mask R-CNN, Fast R-CNN, Faster R-CNN...
detect zones of interest (rectangles), then, for each zone, rectify it, and apply a classification/segmentation tool on it
idem but with attention mechanism: classification features = already computed before ('values'); use same features (pipeline) for detection and classification/segmentation
attention mechanism to know when/where to write/read numbers in the memory
$\implies$ reading = softmax over memory values, with weights depending on the weights for the "address"
GraphCNN
Principles:
a graph with values on nodes (and/or edges) is given as input
each layer computes new values for nodes / edges, as a function of node neighborhoods
same function for all nodes (neighborhoods) : kind of "convolutional"
new node value may depend on edge values also (kind of attention)
idem for edge values (function of node values, edges...)
stack as many layers as needed
max-pooling: means coarsening the graph (deleting nodes)
etc.
many possible constructions, depending on the task / the type of graph (e.g.: molecule vs 3D simulation mesh)
vision transformers (ViT) vs. ResNets : in 2018, ViT show 10% more accuracy : what is it due to exactly?
answer: not to the architecture! but to the training pipeline, that changed within the few years between ResNets and ViT. Hyperparemeters' details: learning rate scheduler, layer width design, ... are very important. Add ViT hyperparameter details to ResNet and their performance increases by 10% as well!
success of vision transformers? they mix tokens, but attention not needed!
replace attention by spatial average pooling (on a 3x3 patch) - value at current position (~ Laplacian)
Other important pieces of design
Loss design:
How is it that, when tackling a classification task, what we want is to obtain the best accuracy, but what we do is optimizing the cross-entropy (which is not the same criterion)? And why does it work?
")
")
")
")
")
")
")
")
")
")
")
")
")
")