| Java Black Jack and Reinforcement Learning |
| Java Black Jack and Reinforcement Learning |
by Frederic Meyer, Logic
Systems Laboratory, EPFL, 1998
Blackjack or twenty-one is a card game where the player attempts to beat the dealer, by obtaining a sum of card values that is equal to or less than 21 so that his total is higher than the dealer's. The probabilistic nature of the game makes it an interesting testbed problem for learning algorithms, though the problem of learning a good playing strategy is not obvious. Learning with a teacher systems are not very useful since the target outputs for a given stage of the game are not known. Instead, the learning system has to explore different actions and develop a certain strategy by selectively retaining the actions that maximize the player's performance. We have explored the use of blackjack as a test bed for learning strategies in neural networks, and specifically with reinforcement learning techniques [1].
This Java applet implements a simplified version of the game of Black
Jack. One or two players can play against the dealer (i.e., the casino).
Though one or both players can be set to be your computer.
By default, the computer plays in a random manner. However, you may
let it play against the dealer and learn to play Black Jack from experience.
The learning algorithm it may use is called the SARSA algorithm, a reinforcement
learning algorithm introduced by G.Rummery and M.Niranjan [2].
A complete introduction to reinforcement learning can be found in the new book by R. Sutton and A. Barto [3]. For futher information on reinforcement learning and Black Jack playing, you may refer to the www page Learning to Play Black Jack with Artificial Neural Networks, also maintained by the LSL lab at the EPFL.
There are two basic options: play and learn. By default, the applet starts with the learn option. You may choose to play just by pressing the left button PLAY in the applet.
Learn
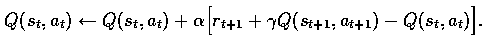
Play
The following gzip'd tar file contains the original Java source code implemented by F. Meyer (frederic.meyer@studi.epfl.ch) during a semester project.
[1] A. Perez-Uribe and E. Sanchez, "Blackjack as a Test Bed for Learning Strategies in Neural Networks", Proceedings of the IEEE International Joint Conference on Neural Networks IJCNN'98 (to appear)
[2] G. Rummery and M. Niranjan, ``On-line q-learning using connectionist systems,'',Tech. Rep. Technical Report CUED/F-INFENG/TR 166, Cambridge, University Engineering Department, 1994.
[3] R.S. Sutton and A.G. Barto, Reinforcement Learning: An Introduction, MIT Press, 1998.
[4] B. Widrow, N. Gupta, and S. Maitra, ``Punish/Reward: Learning with a Critic in Adaptive Threshold Systems,'', IEEE Transactions on Systems, Man and Cybernetics, vol. 3, no.5, pp. 455--465, 1973.