| java -cp . GenRGenS.GenRGenS | |
| or | java -jar GenRGenSvX.X.JAR |
| TYPE | Random model description |
| MARKOV | Markovian random generation. |
| GRAMMAR | Random generation based on context-free grammars. |
| MASTER | Random generation of hierarchical sequences. |
| RATEXP | Prosite patterns and rational expressions. |
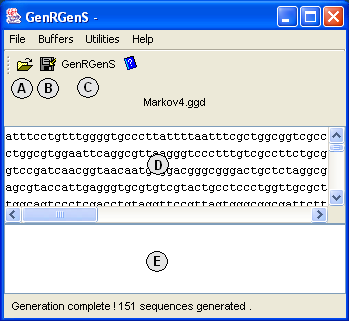
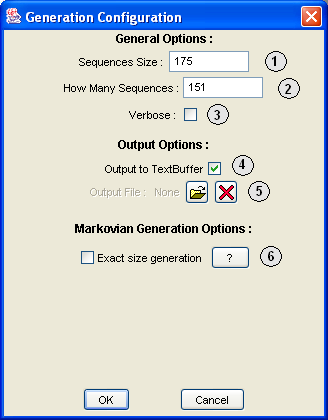
![\begin{figure}
\texttt{
\begin{center}
\begin{tabular}{\vert l\vert l\vert...
...\end{tabular}\\ [0.2cm] \hline
\end{tabular}
\end{center}
}
\end{figure}](img19.gif)