


Dans ce chapitre, nous allons aborder la logique et les formules sur le plan syntaxique, c’est-à-dire que nous chercherons à établir des propriétés logiques des formules (validité, satisfiabilité) par des transformations sans passer par la notion de modèle. Nous étudierons tout d’abord des mises en formes canoniques de formules logiques et en particulier la mise en forme clausale. Nous introduirons également la représentation des formules propositionnelles comme des diagrammes de décision binaires. Finalement nous introduirons des systèmes de déduction pour les formules et en particulier le calcul des séquents.
Dans le chapitre 2 nous avons introduit la forme normale de négation d’une formule. Une formule en forme normale de négation ne contient pas de connecteur ⇒ (ou ⇔) et les seules négations portent sur des symboles de prédicat. Grace aux lois de de Morgan, il est possible de propager les symboles de négation jusqu’aux symboles de prédicat et donc toute formule est équivalente à une formule en forme normale de négation. De plus cette transformation ne change pas (l’ordre de grandeur de) la taille de la formule.
Dans la suite, on parlera d’instance de prédicat pour désigner une formule atomique R(t1,…,tn) avec R un symbole de prédicat. Une formule atomique est soit une instance de prédicat soit de la forme ⊤ ou ⊥. Dans le cas propositionnel, les instances de prédicat sont juste les variables propositionnelles.
Preuve: Pour définir un algorithme qui calcule la forme normale de négation d’une formule, on construit deux fonctions de manière récursive : fnn qui étant donnée une formule quelconque P, construit une formule en forme normale de négation équivalente à P et neg qui étant donnée une formule quelconque P, construit une formule en forme normale de négation équivalente à ¬ P.
|
On montre ensuite par récurrence structurelle sur la formule P que fnn(P) et neg(P) sont en forme normale de négation et que de plus fnn(P)≡ P et neg(P)≡ ¬ P.
Dans le membre droit de chaque équation, il y a le même nombre de connecteurs logiques ∧,∨,∀,∃ que dans le membre gauche. Le symbole d’implication est remplacé par le symbole ∨. On ajoute un symbole de négation uniquement dans le cas de la fonction neg appliquée à une instance de prédicat. Dans le cas de la formule a0⇒ a1⇒…⇒ an) qui a n connecteurs logiques, la forme normale de négation ¬ a0∨¬ a1 …∨ an en a 2n. Cela correspond au pire cas. On peut montrer que si P est une formule avec n connecteurs, alors fnn(P) a au plus 2n connecteurs et neg(P) au plus 2n+1 connecteurs .
D’autre part, les littéraux pourront très souvent se traiter “directement” comme les formules atomiques sans introduire plus de complexité. □
On peut ensuite repousser les négations en commençant par l’extérieur. On obtient la formule : ((¬ p ∨ q) ∧ ¬ p)) ∨ p.
Cette formule est en forme normale de négation. On pourra remarquer que sur le plan sémantique, cette formule peut encore se simplifier en ¬ p ∨ p en utilisant le fait que (a ∨ b)∧ a≡ a puis en ⊤.
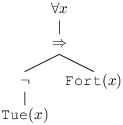
Ci-dessous les représentations sous forme d’arbre, de la formule initiale, puis après élimination des implications et enfin sous forme normale de négation :
 Un litteral tout seul est une clause dans laquelle il n’y a pas de disjonction. En particulier ⊤ et ⊥ sont des clauses. Si on veut faire apparaître une disjonction, on peut toujours rééecrire le littéral l en l∨ ⊥.
Un litteral tout seul est une clause dans laquelle il n’y a pas de disjonction. En particulier ⊤ et ⊥ sont des clauses. Si on veut faire apparaître une disjonction, on peut toujours rééecrire le littéral l en l∨ ⊥.
Les clauses peuvent se simplifier.
La disjonction est associative et commutative on peut donc réarranger les littéraux librement à l’intérieur de la formule sans en changer le sens et en restant syntaxiquement une clause.
On a également P∨ P≡ P, P∨ ¬ P≡ ⊤, P∨ ⊤ ≡ ⊤, P∨ ⊥ ≡ P.
Une clause peut donc soit être de la forme ⊥ ou ⊤, soit s’écrire l1∨ l2∨… ∨ ln avec li un littéral autre que ⊥ ou ⊤. On peut représenter une clause comme un ensemble de litteraux tous distincts. La clause qui correspond à la formule atomique ⊥ est appelée clause vide elle correspond par convention à un ensemble vide de littéraux. Si une clause contient une instance de prédicat et sa négation alors elle est de la forme p∨¬ p∨ Q et se simplifie en ⊤. On appelle clause triviale, une clause qui soit contient le littéral ⊤, soit contient une instance de prédicat p et sa négation ¬ p.
On peut toujours réécrire une clause de manière à ce que chaque instance de prédicat R(t1,…,tn) apparaisse au plus une fois sous forme positive (littéral R(t1,…,tn)) ou négative (littéral ¬ R(t1,…,tn)).
Preuve: Si une instance de prédicat p apparaît deux fois sous forme positive ou deux fois sous forme négative, alors en utilisant q∨ q≡ q on peut retirer une des occurrences sans changer la valeur de la formule.
Si une instance de prédicat p apparaît une fois sous forme positive et une fois sous forme négative alors, en utilisant p∨ ¬ p ≡ ⊤, on peut remplacer ces deux occurrences par la formule ⊤.
Une clause qui contient ⊤ est simplement équivalente à ⊤
Si une clause est de la forme P∨⊥ on peut la simplifier en la clause P. □
Une clause est donc caractérisée par un ensemble d’instances de prédicats, chacun associé à un signe pour
indiquer s’il apparait en position positive ou négative. On peut représenter une clause non triviale par un ensemble d’instances de prédicat associés à des booléens (true si l’instance apparait positivement et false si elle apparait négativement).
Par exemple la clause p∨¬ q peut se représenter par l’ensemble {(p,true);(q,false)}.
Par convention, la clause associée à un ensemble
vide de littéraux est interprétée comme la formule fausse
⊥. En effet une disjonction de formules est vraie lorsque l’une des formules qui forme la disjonction est vraie. S’il n’y a pas de formule, alors la propriété est fausse.
Si L={l1,…,ln} est un ensemble fini de littéraux, on notera L la formule logique correspondant à la clause l1∨ …∨ ln.
Preuve: si L1⊆ L2 alors soit L3 = L2 ∖ L1. On a L2=L1∪ L3 et L_2≡ L_1∨ L_3. Or A⊨ A∨ B, d’où L_1⊨ L_2. □
La réciproque est vraie à condition de la clause correspondant à L2 ne soit pas triviale.
Preuve: si L_1⊨ L_2 et L1⊈L2, alors il existe un littéral l∈ L1 tel que l∉L2.
Comme L2 porte sur des instances de prédicat clos différentes (sinon elle serait triviale), on peut choisir une interprétation J telle que J⊭L_2. Il suffit de choisir l’interprétation J pour que tous les littéraux de L2 soient faux.
L’instance de prédicat du littéral l∈ L1 pourrait apparaître dans L2 mais avec un signe opposé (équivalent à ¬ l).
On a que J⊭¬ l par construction de J donc J⊨ l.
Dans le cas où l’instance de prédicat sous-jacente à l n’apparait pas dans L2 on peut étendre J pour que le littéral l soit vrai.
Comme l∈ L1, et que J⊨ l, on a que J⊨ L_1 et donc une contradiction avec le fait que L_1⊨ L_2 et que J⊭L2.
□
En particulier deux clauses non triviales sont logiquement équivalentes si et seulement si elles correspondent aux mêmes ensembles de littéraux.
Par contre il existe des formules logiques qui ne sont pas équivalentes à des clauses.
En effet si on se donne n variables propositionnelles différentes, on peut construire 3n clauses différentes non équivalentes (pour chaque variable, on choisit si elle apparaît ou non dans la clause, et lorsqu’elle apparaît avec quel signe). Si on ajoute la clause triviale, on a donc 3n+1 clauses qui ne sont pas logiquement équivalentes.
Or le nombre de formules non logiquement équivalentes avec n variables propositionnelles est 22n (nombre de tables de vérité différentes portant sur les 2n interprétations). Pour n=0 et n=1 ces deux nombres coincident, mais pour n=2 on a seulement 10 clauses etpar contre 16 formules non logiquement équivalentes. Il y a donc certaines “vérités” que l’on ne peut pas représenter par une clause. On va voir dans la suite que par contre chaque formule peut être rendue équivalente à la conjonction d’un ensemble fini de clauses.
Dans la suite, on ne s’intéresse qu’à la partie propositionnelle du langage c’est-à-dire à des formules qui ne contiennent pas de quantificateur.
Une formule est dite en forme normale conjonctive (abrégé en FNC, CNF en anglais) si elle s’écrit comme une conjonction de clauses.
On peut représenter une formule en forme normale conjonctive par un ensemble de clauses, on parle alors de forme clausale.
Par convention, une conjonction d’un ensemble vide de formules est définie comme la formule vraie ⊤. En effet, la conjonction de formules est vraie lorsque toutes les formules qui forment la conjonction sont vraies. S’il n’y a pas de formule, alors la propriété est vraie.
On caractérise les formules en forme normale conjonctive en disant que cette formule est une conjonction de disjonction de littéraux. Mais il faut faire attention qu’il y a des cas de limites :
Une formule en forme normale disjonctive peut très bien ne comporter aucun symbole ∨ ni symbole ∧. Une disjonction de littéraux est en forme normale conjonctive, de même pour une conjonction de littéraux. Pour qu’une formule soit en forme normale conjonctive, il faut et il suffit qu’elle ne comporte que les connecteurs logiques ∨, ∧ et des littéraux, et de plus que dans la représentation sous forme d’arbre, il n’y ait pas de connecteur ∧ en dessous d’un connecteur ∨.
Pour démontrer ce résultat, nous allons utiliser une autre propriété qui dit que toute fonction booléenne f à n arguments peut être associée à une formule Q en forme normale conjonctive, telle que la table de vérité de Q correspondra à la fonction f.
On commence par définir plus précisément la notion de fonction booléenne associée à une formule propositionnelle. Cette notion suppose que les variables propositionnelles de la formule sont ordonnées.
Elle est définie par [P]B(b1,…,bn)=val(I{b1,…,bn},P) avec I{b1,…,bn} l’interprétation dans laquelle chaque variable pi a la valeur bi.
La fonction [P]B correspond à la table de vérité de la formule P, dans laquelle les variables sont ordonnées suivant les colonnes et chaque ligne correspond à une entrée de la fonction.
|
|
Preuve: On s’intéresse à l’ensemble Z des n-uplets pour lesquels la fonction f est fausse, c’est-à-dire
| Z |
| {(b1,…,bn) | f(b1,…,bn)=F} |
Dans la table de vérité, il suffit de s’intéresser aux lignes où la valeur de la formule est F. L’ensemble Z est fini. Si cet ensemble est vide alors f=[⊤]B qui est en forme normale conjonctive. On cherche une formule propositionnelle Q qui dépend des variables p1,…,pn correspondant à f. La variable propositionnelle pi correspond à la propriété “le i-ème argument de f est vrai”. La propriété Q doit être vraie lorsque la fonction est vraie et donc doit exprimer que les arguments ne sont pas dans Z. Pour un élément (b1,…,bn), la formule qui dit que les arguments ne correspondent pas à cette valeur est l1 ∨ l2 ∨ … ∨ ln avec li=pi si bi=F et li=¬ pi si bi=V. Cette formule est une clause. Il suffit ensuite de prendre la conjonction des clauses pour chaque élément de Z. □
|
Les lignes qui nous intéressent sont la première et la dernière et on doit trouver une formule qui dit exactement que l’on n’est pas dans un de ces deux cas.
La formule qui dit que l’on n’est pas dans le cas de la ligne 1 est ¬ p1 ∨ ¬ p2 et la formule qui dit que l’on n’est pas dans le cas de la ligne 4 est p1 ∨ p2.
La forme normale conjonctive est donc (¬ p1 ∨ ¬ p2) ∧ (p1 ∨ p2).
Si on parle d’une formule P quelconque, on peut lui associer une fonction booléenne [P]B. Cette fonction booléenne peut, d’après le résultat précédent, se représenter par une formule Q en forme normale conjonctive. On a donc [P]B=[Q]B. Ces deux formules ont même table de vérité par construction et donc sont équivalentes.
Construire la table de vérité d’une formule est trop complexe en général et donc on va plutôt utiliser des méthodes syntaxiques. La formule (a ∧ b) ∨ c n’est pas en forme normale conjonctive car il y a une disjonction qui porte sur une formule qui n’est pas un littéral. La règle de distributivité permet d’inverser les conjonctions et les disjonctions.
|
On en déduit un algorithme de mise en forme normale conjonctive. Pour cela, on construit une fonction fnc(P) qui calcule un ensemble de clauses équivalent à P et on utilise de manière auxiliaire une fonction fnc-neg(P) qui construit un ensemble de clauses équivalent à ¬ P. On aura besoin d’une autre fonction auxiliaire sh, qui prend en argument deux ensembles de clauses E et E′ et qui construit un nouvel ensemble de clauses avec toutes les combinaisons possibles C∨ C′ avec C∈ E et C′∈ E′, c’est-à-dire que sh(E,E′)={C∨ C′|C∈ E, C′∈ E′}. Si E contient n clauses et si E′ contient p clauses alors sh(E,E′) peut contenir jusqu’à n× p clauses (il pourrait y en avoir moins si certaines clauses se simplifient). Pour faire cette opération de manière efficace, il sera utile de rerésenter les clauses comme des ensembles de littéraux, mais dans la suite on considère les clauses comme des formules ordinaires.
|
|
On a recours à deux fonctions pour calculer la forme normale conjonctive car on part d’une formule quelconque qui n’est pas déjà en forme normale de négation.
On définit de manière duale la notion de forme normale disjonctive.
Comme dans le cas des clauses, les conjonctions élémentaires peuvent se simplifier de manière à ne garder que celles dans lesquelles une variable propositionnelle apparaît une seule fois, en effet si p et ¬ p apparaissent dans la même conjonction alors celle-ci est équivalente à ⊥. Comme ⊥∨ Q≡ Q, on peut simplement supprimer la conjonction.
Preuve: On remarque que si P est en forme normale conjonctive, alors la forme normale de négation de ¬ P est en forme normale disjonctive.
Il suffit donc de prendre la forme normale de négation de la négation de la forme normale conjonctive de la formule ¬ P pour obtenir une formule en forme normale disjonctive équivalent à P.
| fnd(P)=fnn(¬ fnc(¬ P)) |
□
Comme précédemment, on peut aussi construire directement la FND à partir de la table de vérité de la formule P. On suppose que les variables propositionnelles sont {p1,…,pn}. On s’intéresse à l’ensemble O des n-uplets (b1,…,bn), pour lesquels la table de vérité donne la valeur vrai. Pour chaque ligne on construit une conjonction élémentaire l1 ∧ l2 ∧ … ∧ ln avec li=pi si bi=V et li=¬ pi si bi=F. Il suffit ensuite de prendre la disjonction de ces formules pour trouver une formule équivalente à P.
| (p1∧ ¬ p2) ∨ (¬ p1 ∧ p2) |
Si une formule est en forme normale disjonctive alors il est facile d’en trouver un modèle. On suppose que les branches de la disjonction sont en forme “simplifiée” c’est-à-dire qu’une variable propositionnelle apparaît dans un seul littéral. Il suffit de choisir une des branches de la disjonction. Pour chaque variable propositionnelle x qui apparaît dans un littéral l on prend dans le modèle x↦ V si l=x et x↦ F si l=¬ x. Il peut arriver qu’il n’y ait aucune composante en forme simplifiée: c’est le cas lorsque la formule initiale est équivalente à ⊥. Dans ce cas, il n’y a pas de modèle, la formule est insatisfiable.
Cependant, la mise en forme normale n’est pas forcément la meilleure manière de trouver un modèle. En effet, cette forme normale peut être exponentiellement plus grosse que la formule initiale. C’est le cas par exemple de la formule (a1∨ b1) ∧…∧ (an ∨ bn) qui a 2n variables et 2n−1 connecteurs. La forme normale disjonctive s’écrit ∨ci∈{ai,bi}(c1∧… ∧ cn) dans laquelle il y a 2n disjonctions.
Lorsqu’une formule propositionnelle est en forme normale conjonctive, il est facile de voir si elle est valide. En effet si l’ensemble des clauses n’est pas vide, on en choisit une qui est de la forme l1∨… ∨ ln que l’on rend fausse en choisissant une interprétation dans laquelle chacun des li est faux ce qui est possible car ils portent tous sur des variables propositionnelles différentes. Si une des clauses de la forme normale conjonctive est fausse alors il en est de même de la formule.
La forme normale conjonctive de la formule (a1 ∧ b1) ∨ … ∨ (an ∧ bn) s’écrit ∧ci∈{ai,bi}c1∨… ∨ cn qui contient 2n clauses. Cette complexité est intrinsèque car liée à la complexité de décider si une formule propositionnelle est valide.
La forme normale conjonctive est équivalente à la formule initiale. Pour la démonstration automatique, cette équivalence n’est pas forcément nécessaire. Si on ne s’intéresse qu’à la satisfiabilité, on peut se permettre de transformer la formule P en une formule Q, telle que P et Q ne sont pas équivalentes, mais seulement equisatisfiables. C’est-à-dire que P est satisfiable si et seulement si Q est satisfiable. Cela nous permet d’introduire de nouvelles variables propositionnelles dans Q pour éviter l’explosion combinatoire.
Dire que P et Q sont équivalents c’est dire que pour toute interprétation I, on a I⊨ P si et seulement si I⊨ Q alors que dire que P et Q sont equisatisfiables c’est dire qu’il existe une interprétation I telle que I⊨ P si et seulement si il existe une interprétation J telle que J⊨ Q. Deux formules équivalentes sont equisatisfiables mais le contraire n’est pas vrai.
La construction se fait de manière récursive sur la structure de la formule que l’on supposera initialement en forme normale de négation. La formule ne contient donc que des conjonctions, des disjonctions et des littéraux.
On remplace chaque conjonction Ri∧ Qi par une nouvelle variable propositionnelle xi et on ajoute des formules qui disent que xi ⇒ (Ri∧ Qi).
| clause(P)= |
|
| {x1 ∨ x2 ∨ x3 ∨ a4 ∨ ¬ b4, ¬ x1 ∨ a1, ¬ x1 ∨ b1, ¬ x2 ∨ a2, ¬ x2 ∨ ¬ b2, ¬ x3 ∨ a3, ¬ x3 ∨ b3 ∨ c } |
Preuve: La définition de la fonction clause est bien formée même si elle ne suit pas le schéma récursif structurel usuel. Elle traite tous les cas (pour une formule propositionnelle en forme normale de négation) et les appels récursifs se font sur des formules qui contiennent strictement moins de connecteurs ∧.
Concernant la taille des clauses obtenues, on observe qu’une variable x est introduite chaque fois qu’une expression P∧ Q apparaît sous une disjonction. On crée alors deux sous problèmes ¬ x ∨ P et ¬ x ∨ Q, cette opération fait disparaître une conjonction sous une disjonction sans changer la situation des autres conjonctions.
Montrons maintenant les liens logiques entre l’ensemble des clauses ainsi obtenu et la formule initiale. Plus précisément, on se donne une interprétation I et on fait le lien entre la vérité de P dans cette interprétation et celle de clause(P). Le cas intéressant est celui dans lequel on introduit une nouvelle variable propositionnelle. Les autres cas se traitent directement ou par hypothèse de récurrence.
Soit P =def A ∨ (R ∧ Q), on suppose qu’il n’y a pas de conjonction dans les formules A, R et Q, on se ramène à ce cas en utilisant les hypothèses de récurrence.
On a clause(P) =def {A ∨ x, ¬ x ∨ R, ¬ x ∨ Q} avec x une variable propositionnelle qui n’apparaît pas dans A ∨ (R ∧ Q).
La formule P est satisfiable exactement lorsque l’ensemble de clauses clause(P) l’est.
□
Les transformations précédentes traitent de la partie propositionnelle des formules (sans quantificateur), nous allons dans cette section montrer comment on traite la partie avec quantificateurs.
Dans la section 2.3.2 nous avons établi des propriétés d’équivalence qui permettent de ramener les quantificateurs en tête de formule. Si x n’est pas libre dans la formule A alors :
|
 Attention la remontée des quantificateurs au travers d’une négation change le quantificateur (loi de de Morgan) de même lorsqu’il est dans la partie gauche d’une implication. La remontée des quantificateurs se fait après avoir mis la formule en forme normale de négation.
Attention la remontée des quantificateurs au travers d’une négation change le quantificateur (loi de de Morgan) de même lorsqu’il est dans la partie gauche d’une implication. La remontée des quantificateurs se fait après avoir mis la formule en forme normale de négation.
 la remontée naïve des quantificateurs peut engendrer une capture des variables : la condition que x n’est pas libre dans la formule A est essentielle.
la remontée naïve des quantificateurs peut engendrer une capture des variables : la condition que x n’est pas libre dans la formule A est essentielle.
Si x est libre dans A (en plus d’être liée dans ∃ x,G(x)) alors on renomme la variable liée en choisissant une variable z qui n’est pas libre dans A ni dans ∃ x,G(x), on a alors A ∨ ∃ x,G(x) = A ∨ ∃ z,G(z)≡ ∃ z,A ∨ G(z)
| Q x1, …, Q xn, A |
Preuve:
On met la formule P en forme normale de négation, on utilise les équivalences rappelées ci-dessus pour remonter les quantificateurs en renommant si nécessaire les variables liées.
□
 La forme prénexe n’est pas unique. L’ordre des quantificateurs en particulier peut varier en fonction de l’ordre dans lequel on choisit de les faire remonter.
La forme prénexe n’est pas unique. L’ordre des quantificateurs en particulier peut varier en fonction de l’ordre dans lequel on choisit de les faire remonter.
On a vu qu’intervertir un quantificateur existentiel et un quantificateur universel en général ne préservait pas l’équivalence entre les formules. Nous allons montrer ici que, si on ne s’intéresse qu’à la satisfiabilité, alors on peut se ramener, grace à une transformation appelée la skolemisation, à une formule prénexe qui n’aura que des quantificateurs universels.
La skolemisation est une opération (introduite par le logicien norvégien Thoraf Albert Skolem au 20ème siècle) qui permet de se débarrasser des quantifications existentielles en enrichissant les signatures et en préservant la satisfiabilité des formules.
L’idée de base est que si on s’intéresse à la formule ∀ x,∃ y,P(x,y) cette formule est vérifiée si pour tout élément d du domaine, on peut trouver un élément e du domaine tel que I,{x↦ d,y↦ e}⊨ P(x,y). En général, la valeur e retenue pour y dépend de la valeur d choisie pour x. On peut exprimer e en fonction de d et donc le problème de trouver un modèle de ∀ x,∃ y,P(x,y) est analogue au problème de trouver un modèle pour ∀ x,P(x,f(x)) dans lequel f est un nouveau symbole de fonction.
De manière plus précise on prouve aisément la propriété de conséquence logique
| ∀ x,P(x,f(x))⊨ ∀ x,∃ y,P(x,y) |
si pour tout x, on a établi que f(x) était dans la relation P avec x, alors a fortiori on sait que pour tout x, il existe un y qui est dans la relation P avec x.
On montre également que si la formule ∀ x,∃ y,P(x,y) est satisfiable alors on peut, à partir d’un modèle de cette formule, trouver un modèle de la formule ∀ x,P(x,f(x)) en choisissant la “bonne” interprétation pour la fonction f.
Pour que cette opération soit licite il suffit que les variables x1,…,xn ne soient pas liées dans B ce qui peut toujours être garanti quite à effectuer des renommages de variables liées dans B.
 Dans beaucoup d’ouvrages, l’élimination du quantificateur existentiel se fait après avoir mis la formule en forme prénexe. On choisit alors l’arité du symbole de fonction introduit en fonction du nombre de quantifications universelles préalables. L’idée étant que si on a une alternance ∀ x,∃ y alors le choix de y peut dépendre de x.
Dans beaucoup d’ouvrages, l’élimination du quantificateur existentiel se fait après avoir mis la formule en forme prénexe. On choisit alors l’arité du symbole de fonction introduit en fonction du nombre de quantifications universelles préalables. L’idée étant que si on a une alternance ∀ x,∃ y alors le choix de y peut dépendre de x.
Dans l’approche présentée ici, on s’intéresse à la sous-formule ∃ y,A et aux dépendances de la condition que doit vérifier y. Si A ne dépend pas de x alors dès qu’on a une valeur pour y qui vérifie A, cette valeur fonctionnera pour toute valeur de x, il n’est donc pas utile de faire dépendre y de la valeur de x.
La méthode prénexe est bien sûr correcte mais peut amener à des dépendances artificielles. Ainsi si on part d’une formule (∀ x, P(x))∨ ∃ y,¬ P(y), la formule ∃ y,¬ P(y) étant close, le symbole introduit pour remplacer l’existentielle est une constante a et on obtient la formule (∀ x, P(x))∨ ¬ P(a). Le domaine de Herbrand associé est constitué de la seule constante a. Une des formes prénexe est (∀ x, ∃ y, P(x)∨ ¬ P(y) et, par la méthode prénexe, il faut introduire un symbole de fonction unaire f et la formule devient (∀ x, P(x)∨ ¬ P(f(x)), le domaine de Herbrand associé est alors infini.
Avoir un domaine de Herbrand plus restreint simplifie la recherche de modèle.
Preuve: La première propriété est une conséquence de B[y← f(x1,…,xn)]⊨ ∃ y,B et du fait que A est en forme normale de négation. En effet on vérifie aisément les propriété de stabilité de la conséquence logique (en l’absence de négation) : si Q⊨ R alors pour n’importe quelle formule P on a
| Q∧ P⊨ R∧ P Q∨ P⊨ R∨ P ∀ x,Q⊨ ∀ x, R ∃ x,Q⊨ ∃ x, R |
Pour la seconde propriété on suppose construit un modèle I de la formule A. La formule B a comme variables libres les variables x1… xn, y. On regarde dans le modèle l’ensemble des n+1-uplets (d1,…,dn,e) tels que I,{x1↦ d1,…,xn↦ dn,y↦ e}⊨ B. On peut à partir de cette relation construire une fonction fJ ∈ Dn→ D telle que I,{x1↦ d1,…,xn↦ dn,y↦ fJ(d1,…,dn)}⊨ B s’il existe e tel que I,{x1↦ d1,…,xn↦ dn,y↦ e}⊨ B et fJ(d1,…,dn)=d avec d une valeur arbitraire de D si pour tout e, I,{x1↦ d1,…,xn↦ dn,y↦ e}⊭B. On peut alors construire une interprétation J sur le même domaine D que I, qui étend l’interprétation I avec l’interprétation du symbole de fonction f comme la fonction fJ.
Cette interprétation rend vraie la formule (∃ y,B) ⇔ B[y← f(x1,…,xn)] pour tout environnement {x1↦ d1,…,xn↦ dn}. Elle rend donc aussi vraie la formule ∀ x1… xn,((∃ y,B) ⇔ B[y← f(x1,…,xn)]). Par ailleurs cette interprétation rend vraie la formule A car J est une extension de I qui est un modèle de A. Comme par ailleurs on peut montrer ∀ x1 … xn,((∃ y,B) ⇔ B[y← f(x1,…,xn)]) ⊨ A⇔ A′ car A′ est obtenue à partir de A en remplaçant ∃ y,B par B[y← f(x1,…,xn)], on en déduit que J est un modèle de A′. □
On peut itérer l’opération précédente pour éliminer tous les quantificateurs existentiels d’une formule. Chaque élimination de quantificateur introduit un nouveau symbole de fonction.
Si on applique ces transformations à une formule A en forme normale de négation, on obtient une formule B sans quantificateur existentiel telle que
Preuve: Il suffit d’éliminer les symboles d’implication et mettre la formule en forme normale négative. On applique ensuite l’élimination des quantificateurs existentiels suivant la procédure vue précédemment. On fait ensuite remonter les quantificateurs universels (en s’assurant au préalable qu’il n’y en n’a pas deux différents qui portent sur une variable de même nom) et en utilisant les équivalences A ∘ ∀ x, B ≡ ∀ x, (A ∘ B) lorsque x n’est pas libre dans B et ∘ ∈ {∨,∧}. Une fois que tous les quantificateurs universels sont en tête (c’est-à-dire que la formule est en forme prénexe) il suffit de les éliminer pour obtenir la formule B. □
Cette opération peut nous permettre de montrer la validité d’une formule. En effet la validité d’une formule A est équivalent à l’insatisfiabilité de la formule ¬ A qui se ramène donc à l’insatisfiabilité de la forme skolémisée de ¬ A. Comme la forme skolémisée est une formule universelle, le théorème de Herbrand nous permet de ramener la satisfiabilité à l’existence d’un modèle construit sur le domaine de Herbrand.
D’après le théorème de Herbrand, la formule ∀ x y, ((¬ P(x) ∨ Q(x))∧ P(y) ∧ ¬ Q(a)) est insatisfiable et donc il en est de même de la formule ¬ A donc A est valide.
Si on se donne un ensemble de formules A1,…,An on peut traiter la skolémisation de manière indépendante pour chaque formule (en introduisant évidemment des symboles différents). On obtient pour chaque Ai une formule Bi sans quantificateurs telle que ∀(Bi)⊨ Ai. On en déduit aisément que :
Dans cette section, nous explorons quelques voies alternatives aux connecteurs usuels pour représenter les formules de la logique. Nous détaillerons sous forme principalement d’exercice la représentation à l’aide de diagrammes binaires de décision.
On a vu au travers des équivalences que de nombreuses formules différentes syntaxiquement pouvaient représenter la même vérité. Une question naturelle qui se pose est alors de savoir si on peut se passer complètement de certains connecteurs logiques et quantificateurs, sans perdre en expressivité.
Les lois de de Morgan nous permettent, à l’aide de la négation, de supprimer les implications, l’un des deux quantificateurs ∀ ou ∃ et l’un des connecteurs ∨ ou ∧.
On peut éliminer la négation en utilisant l’équivalence ¬ A≡ A ⇒⊥ et représenter n’importe quelle formule logique en utilisant uniquement les connecteurs logiques ⊥, ⇒ et un quantificateur au choix. Par exemple la conjonction de deux formules A et B peut se représenter par la formule (A⇒ B⇒ ⊥)⇒⊥ dont on vérifie qu’elle ne peut être vraie que si A⇒ B⇒ ⊥ est faux et donc que A et B sont vrais.
On peut éliminer ⊥ en le remplaçant par a∧¬ a avec a une variable propositionnelle. De même ⊤ peut être remplacé par a∨¬ a ou a⇒ a.
Par contre on ne peut pas se débarrasser simultanément de la négation et de l’implication. En effet, si une formule P n’utilise que les connecteurs ∨ et ∧, alors la fonction booléenne correspondant [P]B est croissante (en considérant l’ordre F<V). Donc on ne peut représenter avec juste ∨ et ∧ des fonctions booléennes comme la négation qui ne sont pas croissantes.
La mise en forme normale conjonctive montre que l’on peut représenter toutes les formules avec les deux quantificateurs, les connecteurs ∨ et ∧ (dont on peut même restreindre l’imbrication) et des négations limitées aux littéraux.
 La skolémisation élimine les quantifications existentielles mais la formule obtenue n’est pas équivalente à la formule initiale, elle peut être fausse dans des interprétations qui rendent vraies la formule initiale.
La skolémisation élimine les quantifications existentielles mais la formule obtenue n’est pas équivalente à la formule initiale, elle peut être fausse dans des interprétations qui rendent vraies la formule initiale.
Il est possible d’introduire d’autres connecteurs propositionnels binaires qui vont nous donner des représentations différentes des formules.
Le plus connu est le ou exclusif noté ⊕ qui est défini pour satisfaire les équivalences
| x⊕ y ≡ x∨ y ∧ ¬ (x∧ y) ≡ (x∧ ¬ y) ∨ (¬ x ∧ y) ≡ ¬ (x⇔ y) |
.
On peut coder toutes les fonctions booléennes à l’aide des seuls connecteurs ⊕,∧,⊤. Les opérations ⊕ et ∧ munissent l’ensemble des booléens d’une structure d’anneau de Boole.
L’opération ⊕ est utile comme opérateur simple de cryptographie bit-à-bit d’un message. On utilise le fait que x⊕ x=⊥ et x⊕ ⊥ =x, ainsi que l’associativité de ⊕. Si on dispose d’une clé secrète key, le message m crypté sera m⊕ key, il pourra être décrypté en lui appliquant la même opération (m⊕ key)⊕ key
Il est même possible de représenter toutes les fonctions booléennes à l’aide uniquement de variables propositionnelles et d’un unique connecteur binaire : la barre de Sheffer x∣ y également appelée opérateur NAND et qui est défini comme la négation de la conjonction x∣ y≡ ¬(x∧ y), on vérifie aisément que x∣ x≡ ¬ x, x∣ ¬ x≡ ⊤, (x∣ y)∣(x∣ y)≡ ¬ (x∣ y) ≡ x∧ y et ces constructions sont suffisantes pour reconstruire toutes les formules propositionnelles.
Une représentation alternative de la partie propositionnelle des formules est l’utilisation d’un connecteur de conditionnelle à trois arguments. IF(P,Q,R). C’est d’une part une construction naturelle dans les langages de programmation, mais surtout, en limitant les conditionnelles à porter sur des variables propositionnelles, cette représentation des formules propositionnelles devient très efficace. Elle est largement utilisée en démonstration automatique.
On introduit un connecteur logique IF(P,Q,R) qui a la même table de vérité que la formule (P∧ Q) ∨ (¬ P ∧ R), ou de manière équivalente à (P⇒ Q) ∧ (¬ P ⇒ R).
On représente n’importe quelle fonction booléenne en utilisant ce connecteur ainsi que les formules ⊥ et ⊤. Pour s’en convaincre il suffit de remarquer que :
|
On remarque ensuite qu’il est possible de simplifier la partie condition, en effet si le premier argument du IF n’est pas une variable propositionnelle alors une des équivalences suivantes va s’appliquer :
| IF(⊤,P,Q)≡ P IF(⊥,P,Q)≡ Q IF(IF(B,P,Q),R,S)≡IF(B,IF(P,R,S),IF(Q,R,S)) |
On peut donc se ramener à des expressions conditionnelles dans lesquelles la condition est toujours une variable propositionnelle. On remarquera néanmoins que construire cette forme “simplifiée” peut faire grossir la taille de la formule de manière exponentielle.
En effet si on se donne des variables propositionnelles p,p1,…,pk,q1,…,qk, on peut construire une suite de formules A0=p, An+1=IF(An,pn,qn). La formule An contient n connecteurs IF et chaque variable propositionnelle apparaît exactement une fois.
Si on veut simplifier An+1, on obtiendra la suite de transformations suivante :
|
A chaque étape, on diminue de un le nombre de IF dans la condition mais on double le nombre de ceux qui apparaissent dans les branches et on en ajoute deux supplémentaires.
Un des enjeux sera donc de limiter cette explosion par le choix d’une méthode de construction et d’une représentation adéquate. Néanmoins, on gardera en tête que le comportement exponentiel dans le pire des cas est de toute manière inévitable lorsqu’on veut résoudre des problèmes généraux du calcul propositionnel.
On s’intéresse dans la suite à des formules du calcul propositionnel, construit sur un ensemble de variables propositionnelles totalement ordonné.
L’arbre de décision binaire définit une fonction booléenne sur l’ensemble des variables présentes dans l’arbre. Lorsque l’on passe un nœud étiqueté par la variable x, le sous arbre gauche correspond au cas où x a la valeur V et le sous-arbre droit au cas où x a la valeur F. Une branche de l’arbre définit donc une valeur pour les variables propositionnelles et la valeur de la fonction est déterminée par le booléen présent au niveau de la feuille. Comme toutes les variables ne sont pas forcément présentes dans une branche, celle-ci représente en général une valeur pour un ensemble d’arguments.
| [.p [.q V V ] [.q F V ] ] [.p V [.q F V ] ] |
|
On définit simplement de manière récursive la valeur vald(I,t) d’un arbre de décision binaire t dans une interprétation des variabbles propositionnelles I :
|
Comme pour les formules ordinaires, pour une interprétation I et un arbre t, on notera I⊨ t la propriété vald(I,t)=V.
Transformer cette fonction pour obtenir directement un ensemble de clauses représentant la forme normale conjonctive.
Les arbres de décision binaire ont deux défauts : des arbres différents peuvent représenter des formules équivalentes (par exemple IF(x,P,P)≡ P) et leur taille est en général exponentielle en le nombre de variables propositionnelles.
Pour construire un OBDD à partir d’une formule propositionnelle P, il suffit de partir de la plus petite variable x qui apparaît dans la formule et de construire récursivement l’OBDD PV correspondant à la formule P[x← ⊤] pour la branche “vrai” et l’OBDD PF correspondant à la formule P[x← ⊥] pour la branche “faux”. Si les deux OBDDs sont les mêmes alors PV est le résultat attendu, sinon on introduit le nœud x avec un arc plein vers PV et un arc pointillé vers PF.
On s’intéresse maintenant à la possibilité de déduire de manière syntaxique qu’une formule P est une conséquence logique d’un ensemble de formules E, c’est-à-dire que la formule P sera vraie dans toute interprétation qui rend les formules de E vraies.
Nous allons introduire des systèmes de déduction qui définissent des relations sur les formules en se donnant un certain nombre de règles du jeu, liées à leur structure logique.
Les relations peuvent porter sur les formules elle-mêmes ou bien sur une structure un peu plus compliquée appelée séquent qui prend en compte à la fois un ensemble d’hypothèses et une ou même un ensemble de conclusions.
Avant d’introduire les systèmes spécifiques à la logique, nous donnons le cadre général des définitions par règles d’inférence.
Les règles d’inférence sont une manière de définir une relation mathématique R qui est très utile en informatique théorique. Dans tout ce qui suit, on s’intéresse à des propriétés mathématiques générales et non pas à des formules de la logique (même si les notations peuvent se ressembler). Une relation n-aire R est juste un sous ensemble du produit de n ensembles A1×…× An.
Dans la suite on considère une relation sur un ensemble A qui pourra être choisi si nécessaire comme un ensemble produit. La relation est donc simplement un sous-ensemble R de A.
On écrira de manière générique R(t) la propriété qui dit que t∈ R.
On se donne donc un ensemble A, on veut définir une relation R sous-ensemble de A. L’idée est de caractériser la relation R par des conditions que cette relation R doit vérifier.
Ces conditions sont traditionnellement représentées par des règles d’inférence. Une règle d’inférence se présente sous la forme d’une fraction :
|
Le dénominateur (aussi appelé la conclusion de la règle) est forcément un cas particulier de la relation que l’on cherche à définir. Le numérateur contient un nombre quelconque de conditions (que l’on appelera aussi les prémisses de la règle d’inférence).
La règle peut utiliser des variables mathématiques x1… xp, appelés paramètres.
L’interprétation de la règle est que pour n’importe quelles valeurs possibles de x1… xp, si les conditions P1… Pk sont vérifiées alors la propriété R(t) est également vérifiée.
S’il n’y a aucune condition k=0, cela veut dire que R(t) est toujours vrai.
Par exemple on peut définir le fait qu’un nombre entier est pair avec les règles d’inférences suivantes :
| (p0) |
| (pS) |
|
Dans la deuxième règle, x est est un paramètre représentant n’importe quel entier, c’est-à-dire que la règle est valable si on remplace x par n’importe quel terme. Par exemple
| pair(2) |
| pair(4) |
mais aussi
| pair(1) |
| pair(3) |
.
Il y a plusieurs relations qui vérifient ces propriétés (par exemple l’ensemble des entiers ℕ). La relation définie par les règles d’inférence est par construction l’intersection de toutes les relations qui vérifient les conditions. Ce sera la la plus petite relation (au sens de l’inclusion) ayant cette propriété.
Le fait qu’une telle relation existe et a les bonnes propriétés est un théorème qui nécessite des conditions supplémentaires sur Pi. Nous nous intéresserons au cas simple dans lequel chaque Pi est soit un cas particulier R(u) de la relation à définir, soit une condition auxiliaire qui ne parle pas de R.
Chaque règle d’inférence est de la forme
| R(u1)… R(un) P1… Pk |
| R(t) |
où t,u1,…,un∈ A et P1,…,Pk sont des conditions auxiliaires qui ne mentionnent pas R.
La règle d’inférence peut être paramétrée par des variables mathématiques x1… xp.
Chaque règle d’inférence représente une condition sur la relation R qui s’énonce ainsi : pour n’importe quelles valeurs possibles de x1… xp, si les conditions R(u1)… R(un) et P1… Pk sont vérifiées alors la propriété R(t) est également vérifiée.
La relation R ainsi définie est la plus petite relation qui vérifie l’ensemble des conditions associées aux règles d’inférence.
Preuve: Cette définition nécessite une preuve à savoir l’existence d’une plus petite relation qui vérifie les conditions associées aux règles d’inférence.
On note Cond(R) l’ensemble des conditions associées aux règles d’inférence de R et on note R0 l’intersection ∩{R⊆ A | Cond(R)} de toutes les relations qui vérifient la condition.
Cette intersection est bien définie car il y a au moins une relation qui vérifie la condition à savoir la relation qui correspond à l’ensemble A tout entier.
Il faut montrer que R0 vérifie les conditions.
Une première remarque est que par définition de l’intersection, on a que R0(t) est vérifié si et seulement si R(t) est vérifié pour toutes les relations R qui vérifient Cond(R).
Soit une règle d’inférence
| P1… Pk |
| R(t) |
paramétrée par des variables x1… xp.
Soit donc x1… xp quelconques, on suppose que les prémisses P1… Pk sont vérifiées pour la relation R0 et on doit montrer que R0(t) est vérifié.
Par définition de l’intersection on doit montrer que R(t) est vrai pour n’importe quelle relation qui satisfait les conditions Cond(R).
Parmi les conditions que satisfait R on a la règle d’inférence
| P1… Pk |
| R(t) |
, donc pour montrer R(t), il suffit de montrer que les prémisses P1… Pk sont vérifiées pour la relation R.
Les prémisses soit ne mentionnent pas R soit sont de la forme R(u).
On en déduit que R vérifie les prémisses de la règle donc aussi la conclusion et donc comme R(t) est vrai pour toute relation qui vérifie les conditions, on a aussi R0(t). Ce qui conclut la démonstration du fait que R0 vérifie les conditions des règles d’inférence. □
Ce résultat se généralise au cas où les prémisses sont des propriétés croissantes de la relation à définir (c’est-à-dire que si on a une condition P[R] qui dépend de la relation R alors si R⊆ S et P[R] est vérifié, il en est de même de P[S]. Une condition pourrait donc être de la forme ∀ y, R(u)∨ B, voir faire apparaître la relation R à gauche d’un nombre pair de symboles d’implication.
Par contre la croissance des prémisses est essentielle. Si on essaie de définir de la même manière une relation être pair avec les deux règles suivantes :
|
|
La relation “tout le temps vraie” (pair=ℕ) vérifie ces conditions, de même pour la relation “ëtre pair” qui contient tous les entiers pairs (pair={2k|k∈ℕ}) et qui vérifie les conditions. Mais de manière plus surprenante, la relation “ëtre 0 ou impair” qui contient 0 ainsi que tous les entiers impairs (pair={0}∪ {2k+1|k∈ℕ}) vérifie aussi les conditions. Donc si on prend l’intersection de toutes les relations qui vérifient les conditions, il reste juste la relation qui contient 0. Mais cette relation ne vérifie pas les conditions puisque elle ne contient pas 1 et donc elle devrait contenir 1+1=2 ce qui n’est pas le cas.
Dans nos exemples les seules prémisses qui mentionnent la relation à définir R sont de la forme R(u) et donc ne présentent pas ce problème.
Le résultat précédent est un cas particulier d’un théorème plus général, appelé théorème de point fixe de Tarski (attribué à Bronisłav Knaster et Alfred Tarski), qui établit l’existence d’un point fixe pour toute fonction monotone sur un espace ayant de bonnes propriétés.
Toute fonction croissante de E dans E admet un plus petit et un plus grand point fixe.
Preuve: Par définition la borne supérieure est le plus petit des majorants c’est donc un majorant (pour tout x∈ A, on a x≤ sup(A)) et c’est le plus petit donc si on a e∈ E qui est un majorant (pour tout x∈ A, on a x≤ e) alors sup(A)≤ e.
L’existence d’une borne supérieure implique l’existence d’une borne inférieure pour tout ensemble (la borne inférieure de l’ensemble A est la borne supérieure de l’ensemble des minorants de A), on la notera inf(A).
On regarde l’ensemble A={x∈ E|f(x)≤ x} et on pose a=inf(A).
Les propriétés de la borne inférieure sont
La preuve suit alors les étapes suivantes :
f(a)∈ A et par la première propriété, on a donc a≤ f(a)
□
Lorsque l’on introduit un système d’inférence pour définir une relation, on utilise ces mêmes règles d’inférence pour justifier que la relation est vérifiée.
De manière générale, une preuve de R(a) se construit par étapes comme une séquence de faits (dérivation)
de la forme R(b1),…,R(bn) où chaque R(bi) s’obtient par une règle dont les prémisses sont dans R(b1),…,R(bi−1). En pratique on représente la dérivation comme un arbre dont la racine est la conclusion et chaque nœud correspond à un cas particulier d’une règle d’inférence.
|
Chaque noeud correspond à un cas particulier d’une règle d’inférence
| R(u1)… R(un) P1… Pk |
| R(t) |
.
C’est-à-dire qu’il existe des valeurs pour les paramètres x1…,xp de la règle pour lesquelles t=a.
On écrit
| R(b1)… R(bn) P′1… P′k |
| R(a) |
la règle obtenue pour ce cas particulier des paramètres.
Pour que la règle soit applicable, il faut que l’ensemble des conditions auxiliaires P′1… P′k soient vérifiées.
Un nœud correspondant à cette règle aura n fils (un fils par prémisse de la forme R(bi)), chaque fils est étiqueté par cette prémisse.
L’arbre est complet s’il n’y a plus de feuilles (application de règles sans prémisse portant sur R, c’est-à-dire n=0) et il constitue alors une preuve que la racine est dans la relation.
Un arbre incomplet constitue une preuve du fait que si l’ensemble des propriétés correspondant aux feuilles de l’arbre sont vérifiées alors la propriété à la racine de l’arbre est aussi vérifiée.
L’arbre se dessine en juxtaposant les règles d’inférence instanciées, il est recommandé de nommer chaque règle et de reporter le nom en marge de la barre de fraction. De même les conditions qui doivent être vérifiées peuvent être rappelées en annotation du nœud. On peut aussi noter les valeurs prises par les paramètres de la règle de manière à les reporter uniformément dans les prémisses et la conclusion.
Le fait que la relation définie est la plus petite qui satisfait les règles d’inférence, nous permet également de dériver un schéma de preuve puissant qui dit que si on se donne une autre relation S qui vérifie les mêmes conditions associées aux règle d’inférence que R alors
pour tout t, si R(t) on a aussi S(t). On appellera ce schéma de preuve, une preuve par minimalité de la définition de R.
Dans le cas de la définition de pair, cela se traduit par le principe suivant :
Par exemple on peut utiliser ce principe pour prouver que si n vérifie pair alors il existe k tel que n=2k. Il suffit de vérifier les deux conditions du principe précédent avec pour propriété φ(n), l’énoncé “il existe k tel que n=2k”, c’est-à-dire :
L’exemple pair est particulièrement élémentaire et on peut trouver d’autre formulations équivalentes sans utiliser de règles d’inférence comme ∃ k, n=2k ou bien n mod 2=0.
| R(u1)… R(un) P1… Pk |
| R(t) |
pour n’importe quelles valeurs des paramètres x1,…,xp qui vérifients les prémisses de la règle (on a R(u1)… R(un) et P1… Pk) et tels que φ(u1)… φ(un) sont vérifiés, alors φ(t) est vérifié
Les systèmes d’inférence sont utiles pour définir des relations générales qui ne sont pas des fonctions. Par exemple, si on suppose donnée une relation ami(x,y) qui représente le fait que x a déclaré que y est son ami dans un réseau social. Alors on peut simplement définir une relation reseau(x,y) qui représente le fait qu’il y a une chaîne d’amitiés entre x et y.
Il suffit de traduire les conditions suivantes :
Ce qui s’exprime par les règles d’inférence suivantes :
|
|
Il peut y avoir plusieurs systèmes d’inférence différents qui définissent la même relation (au sens où on peut prouver reseau(x,y) si et seulement si reseau1(x,y) si et seulement si reseau2(x,y)) :
|
|
ou encore :
|
|
Les systèmes d’inférence ont des applications en logique pour définir des systèmes de déduction, ils sont également beaucoup utilisés en informatique pour modéliser la sémantique des langages de programmation, par exemple les règles de typage ou les traductions entre langages en particulier dans le domaine de la compilation. C’est aussi une technique qui permet de modéliser des systèmes informatiques ayant des comportements non déterministes (systèmes parallèles et communicants).
On va s’intéresser ici à des systèmes d’inférence qui vont nous permettre de prouver la validité de formules en utilisant leurs propriétés syntaxiques. On parlera de système de déduction logique, ou système de preuve.
Lorsqu’on fait un raisonnement, on a pour habitude de travailler de manière générale avec un ensemble d’hypothèses Γ et une formule P.
La formule associée au séquent P1,…,Pn ⊢ Q est définie comme (P1∧ … ∧ Pn)⇒ Q
Un séquent Γ⊢ P est valide si P est conséquence logique de Γ (Γ⊨ P) ou de manière équivalente si la formule associée au séquent est valide.
Si Γ est un ensemble fini de formules {A1,…,An}, on écrit A1,…,An⊢ P pour la propriété Γ ⊢ P. Si Γ est l’ensemble vide, on note simplement ⊢ P. Si Q est une formule, on note Γ,Q l’ensemble Γ auquel on a ajouté la formule Q soit Γ∪{Q} de même si Γ et Δ sont des ensembles finis de formules, on note Γ,Δ l’ensemble Γ∪Δ formé par leur union.
L’ensemble des variables libres d’un ensemble de formules Γ est par définition l’union des variables libres des formules de Γ, il est note Vl(Γ).
Nous allons définir par des systèmes d’inférence des relations pour capturer l’ensemble des séquents “prouvables”. Traditionnellement, on n’introduit pas de notation supplémentaire. Ainsi suivant le contexte, la notation Γ ⊢ P représentera l’objet séquent (un couple formé d’un ensemble d’hypothèses et d’une conclusion) ou bien la propriété qui dit que ce séquent en prouvable dans le système considéré.
Un arbre de preuve pour un séquent Γ⊢ P est un arbre de dérivation complet qui établit que le séquent est prouvable.
Faire une preuve d’une formule P se fera en construisant un arbre de dérivation dont la racine sera le séquent ⊢ P (sans hypothèse).
On n’introduira évidemment que des systèmes corrects : tout séquent prouvable est valide et on cherchera à ce que les systèmes soient complets à savoir que tout séquent valide soit prouvable.
 Les règles d’inférence pour faire des preuves reposent sur la syntaxe des formules, ainsi il n’est pas correct de transformer dans un séquent une formule par une autre formule équivalente (sauf si une règle nous autorise explicitement à le faire).
Les règles d’inférence pour faire des preuves reposent sur la syntaxe des formules, ainsi il n’est pas correct de transformer dans un séquent une formule par une autre formule équivalente (sauf si une règle nous autorise explicitement à le faire).
On peut définir un système simple pour dériver des formules valides dans une logique minimale (avec juste des variables propositionnelles et le connecteur ⇒). Soit Min l’ensemble des formules de la logique minimale. On définit une relation sur cet ensemble, qui va représenter des formules prouvables.
La relation que l’on définit est notée ⊢ P avec P∈Min. Elle est donnée par le système d’inférence suivant qui comporte deux “axiomes” (des règles sans prémisses) et la règle de Modus Ponens :
| (K) |
| (S) |
| (mp) |
|
|
Si on veut montrer que toute formule P telle que ⊢ P est prouvable est aussi valide (si ⊢ P alors ⊨ P) on va le faire en utilisant le principe de minimalité associé à la définition de ⊢.
Il nous suffit de montrer les trois propriétés, une pour chaque règle d’inférence pour n’importe quelles formules p, q et r.
ce qui se vérifie simplement.
On étend ce système au cas du raisonnement sous hypothèses. Les règles vues précédemment sont transformées pour intégrer les hypothèses. Une règle est ajoutée qui dit que toute formule qui apparaît dans les hypothèses Γ est prouvable.
| (hyp) |
| (K) |
| (S) |
| (mp) |
|
Si une formule est prouvable à partir d’hypothèses Γ est est a fortiori prouvable si on ajoute des hypothèses. Cette propriété essentielle s’appelle l’affaiblissement.
Preuve: La preuve se fait simplement en utilisant le principe de minimalité associé à la définition. Soit Γ et Δ deux ensembles de formules telles que Γ⊆ Δ, la propriété à prouver est Δ⊢ p.
On vérifie simplement que la propriété Δ⊢ p est bien stable pour les quatre règles d’inférence qui définissent la relation Γ⊢ p.
Le seul cas non trivial est celui de la règle hypothèse pour laquelle on a p∈Γ, comme Γ⊆ Δ, on a aussi p∈Δ, on en déduit Δ⊢ p. □
Une autre propriété d’affaiblissement qui nous sera utile est la suivante.
Preuve: C’est une simple déduction sous hypothèse :
|
□
Preuve:
| Γ,p ⊢ r⇒ q Γ,p⊢ r |
| Γ,p ⊢ q |
on a donc Γ ⊢ p⇒ r⇒ q et Γ⊢ p⇒ r, on construit alors la dérivation suivante :
|
□
Dans le système de Hilbert, la relation de déduction est définie avec un ensemble fixe d’hypothèses, le théorème de déduction peut se voir comme une règle “dérivée” qui transforme simultanément l’ensemble des hypothèses et la conclusion.
L’idée des calculs de séquents est d’intégrer dans les règles d’inférence des manipulations sur l’ensemble des hypothèses. Il en existe plusieurs variantes. Nous présentons ici la déduction naturelle et le calcul des séquents à conclusions multiples, deux systèmes qui ont été introduits par Gerhart Gentzen.
Nous donnons ici les principes de base de la déduction naturelle, un système qui est proche du raisonnement mathématique usuel.
Nous allons définir une relation qui correspond au sous-ensemble des séquents “prouvables en déduction naturelle”. Dans cette section, la notation Γ ⊢ P représente soit l’objet séquent, soit la propriété qui dit que ce séquent en prouvable en déduction naturelle.
Nous présentons chacune des règles sous forme de règles d’inférence
|
qui permet de construire un arbre de preuve dont la racine (en bas) représente le séquent que l’on cherche à justifier et les feuilles sont des conditions suffisantes.
Une première série de règles permet de terminer une preuve dans les cas “élémentaires” :
| (hyp) |
|
| (ax) |
|
Les règles suivantes expliquent comment ramener la preuve d’une formule à des preuves de certaines de ses sous-formules. On les appelle des règles d’introduction :
| (∧ I) |
|
| (∨ Ig) |
| (∨ Id) |
|
| (¬ I) |
|
| (⇒ I) |
|
| (∀ I) |
|
| ( ∃ I) |
|
Ces règles sont suffisantes pour prouver les propriétés suivantes (sans hypothèses) :
mais elles ne sont pas suffisantes pour montrer une propriété comme (A ∧ B) ⇒ (A ∨ B). En effet elles se contentent d’ajouter des connecteurs dans la conclusion, nous allons expliquer maintenant des règles qui permettent d”’enlever” des connecteurs.
Les règles suivantes expliquent comment utiliser une preuve d’une formule en fonction du connecteur principal de cette formule. On appelle ces règles des règles d’élimination.
| (⊥ E) |
|
| ( ¬ E) |
|
| (∧ Eg) |
| (∧ Ed) |
|
| (∨ E) |
|
| (⇒ E) |
|
| (∀ E) |
|
| (∃ E) |
|
Enfin, les règles précédentes ne suffisent pas à prouver toutes les formules valides (par exemple A∨¬ A), il faut y ajouter le schéma de raisonnement classique qui capture ce que l’on appelle le raisonnement par l’absurde. Si on veut prouver A alors on peut supposer ¬ A et en déduire une contradiction.
|
On remarque que si une formule A est une conséquence d’hypothèses Γ alors a fortiori A est une conséquence d’un ensemble d’hypothèses Δ qui contient les hypothèses de Γ. C’est vrai pour la règle hypothèse, puis c’est préservé par toutes les règles. Ce résultat peut s’énoncer de la manière suivante :
On peut donc oublier des hypothèses inutiles lorsque l’on construit une preuve. Attention par contre à ne pas supprimer d’hypothèse qui peuvent être nécessaires pour compléter la preuve.
À partir des règles de base que l’on s’est données, on peut déduire d’autres schémas de preuve naturels que l’on pourra utiliser librement.
| Cut |
|
|
| ⊥ ∈ Γ |
| Γ ⊢ C |
| Γ ⊢ A ¬ A ∈ Γ |
| Γ ⊢ C |
| Γ,A,B ⊢ C A∧ B ∈ Γ |
| Γ ⊢ C |
| Γ,A ⊢ C Γ,B ⊢ C A∨ B ∈ Γ |
| Γ ⊢ C |
| Γ,B ⊢ C Γ ⊢ A A ⇒ B ∈ Γ |
| Γ ⊢ C |
| Γ,P[x← t] ⊢ C ∀ x, P ∈ Γ |
| Γ ⊢ C |
| Γ,P ⊢ C x ∉Vl(Γ,C) ∃ x, P ∈ Γ |
| Γ ⊢ C |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dérivation de ¬ A ∨ B ⇒ A ⇒ B.
Au départ il n’y a pas d’hypothèse, le séquent à montrer est ⊢ ¬ A ∨ B ⇒ A ⇒ B.
On commence par faire des introductions du connecteur ⇒, on a donc deux hypothèses ¬ A ∨ B, A et on doit montrer B.
On raisonne par cas sur la preuve de ¬ A ∨ B (vraie par hypothèse).
L’arbre de preuve correspondant s’écrit :
|
La déduction naturelle a des liens très étroits avec la programmation fonctionnelle typée. Cette correspondance est connue sous le nom d’isomorphisme de Curry-Howard. Plus précisément on peut faire correspondre les formules logiques avec des types. Par exemple l’implication A⇒ B correspond au type des fonctions de A dans B et la conjonction A∧ B correspond au type des paires formées d’élément de A et de B. Les hypothèses du séquent correspondent aux types des variables du programme. Chaque règle de preuve correspond à une construction de programme. Ainsi une preuve d’un séquent va correspondre à un programme bien typé.
Les calculs qui peuvent se faire dans le langage de programmation correspondent à des transformations de preuves.
Le fait que les constructions de programmes fonctionnels soient plus sûres que leur correspondant impératifs ou objets et que leur preuve se fasse plus simplement est lié à cette similarité avec nos modes de raisonnement usuels. Néanmoins, afin de permettre l’expression de l’ensemble des fonctions calculables, les langages de programmation autorisent des constructions récursives générales et boucles non bornées. Les méthodes de peuves sont elles beaucoup plus restrictives afin de rester correctes.
L’isomorhisme de Curry-Howard est également à la base d’un système de preuve interactif comme Coq (ou Lean). La preuve est représentée par un terme fonctionnel qui doit satisfaire des règles de typage pour garantir la correction de la preuve.
Les règles de bases de la déduction naturelle permettent de faire naviguer des formules entre hypothèse et conclusion mais ne transforment pas la structure des formules dans les hypothèses. Or de telles règles sont utiles (nous les avons d’ailleurs fait apparaître comme des règles dérivées).
Par ailleurs la déduction naturelle repose sur un certain nombre de règles qui ne sont pas “inversibles” c’est-à-dire que la conclusion peut être vraie sans que les prémisses le soient. C’est le cas des règles d’introduction de la disjonction et de l’existentielle ou des règles d’élimination de la conjonction, de la quantification universelle et de l’implication.
|
|
|
|
|
|
|
L’utilisation de ces règles peut nous mener à des impasses. L’utilisation des règles d’élimination d’hypothèses pour la conjonction et la quantification universelle permet de traiter ces connecteurs sans perdre dinformation.
| ∀ H |
|
Mais cela ne résoud pas les questions de la disjonction, de l’existentielle et de l’implication.
On voit qu’il y a une disymétrie dans les séquents entre les hypothèses qui comportent plusieurs formules et la conclusion qui est limitée à une seule formule. L’idée du calcul des séquents est d’autoriser aussi un ensemble de formules à droite du symbole ⊢.
La formule associée au séquent multi-conclusions P1,…,Pn ⊢ Q1,…,Qp est définie comme (P1∧ … ∧ Pn)⇒ (Q1∨…∨ Qp). Si Δ=∅ (p=0) alors (Q1∨…∨ Qp) est par définition la formule ⊥ et la formule associée au séquent s’écrit (P1∧ … ∧ Pn)⇒ ⊥ ce qui est équivalent à ¬ (P1∧ … ∧ Pn).
Un séquent Γ⊢ Δ est valide si et seulement si la formule associée au séquent est valide ou, de manière équivalente, si pour toute interprétation I telle que I⊨Γ, il existe P∈Δ tel que I⊨ P.
On voit donc que l’ensemble des hypothèses à gauche du signe ⊢ est interprété comme une conjonction (toutes les hypothèses sont vraies) alors que l’ensemble des conclusions à droite du signe ⊢ est interprété comme une disjonction (au moins une des conclusions est vraie).
Les règles vont alors pouvoir prendre une forme symétrique entre gauche et droite. Chaque règle porte sur une des formules dans les hypothèses (on dit que c’est une règle gauche) ou dans les conclusions (on dit que c’est une règle droite) et va éliminer le connecteur ou quantificateur principal de cette formule pour se ramener à un ou plusieurs séquents à prouver.
Nous appellerons système G le système de déduction défini par l’ensemble des règles suivantes.
Les règles permettent de décomposer les connecteurs soit dans la partie gauche du séquent, soit dans la partie droite. On utilise des lettres grecques Γ, Δ pour représenter des ensembles arbitraires (finis) de formules. On rappelle que l’ordre des formules n’intervient pas dans la définition d’un ensemble, ainsi les ensembles A,B,C et C,A,B sont égaux.
Un premier jeu de règles permet de conclure une preuve dans des cas triviaux (une contradiction dans les hypothèse, une propriété triviale dans les conclusion ou bien une conclusion qui est également une hypothèse):
| (Jok) |
| (Triv) |
| (Hyp) |
|
Nous donnons ensuite les règles pour chaque connecteur : on retrouve la règle Jok qui est la règle gauche de ⊥ et la règle Triv qui est la règle droite de ⊤.
|
|
|
|
On établit simplement des propriétés sur la structure des preuves. Un séquent prouvable le reste si on ajoute des hypothèses ou des conclusions.
Preuve: On utilise une preuve par minimalité de la définition de Γ ⊢ Δ. □
Si un séquent contient des variables libres et est prouvable alors il en est de même pour le séquent dans lequel la variable libre a été remplacée par un terme arbitraire.
Preuve: On utilise une preuve par minimalité de la définition de Γ ⊢ Δ. □
Une autre propriété importante est que toutes les règles sont inversibles c’est-à-dire qu’une interprétation rend vrai un séquent en conclusion d’une règle si et seulement si elle rend vrais les séquents qui apparaissent dans les prémisses.
Preuve: On regarde les règles une par une en utilisant les propriétés des connecteurs et quantificateurs.
Si on s’intéresse à la règle gauche de l’implication :
| Γ ⊢ Δ, A Γ,B ⊢ Δ |
| Γ,A⇒ B ⊢ Δ |
Les prémisses se traduisent par les formules M ⇒ P ∨ A et B ∧ M ⇒ P la conclusion se traduit par la formule (A⇒ B) ∧ M ⇒ P On vérifie que les formules (M ⇒ P ∨ A) ∧ (B ∧ M ⇒ P) et (A⇒ B) ∧ M ⇒ P sont équivalentes (par exemple à l’aide de tables de vérité).
Une autre manière de raisonner est d’analyser directement la valeur de vérité d’un séquent. Un séquent est faux dans une interprétation, si et seulement si toutes les hypothèses sont vraies et toutes les conclusions sont fausses.
On peut donc faire directement les tables de vérité des trois séquents qui apparaissent dans la règle gauche de l’implication et on remarque que le séquent conclusion est vrai si et seulement si les deux séquents de prémisses sont vrais.
|
| (∀ g) |
| (∃ d) |
|
□
 Des présentations alternatives du calcul des séquents utilisent plutôt des multi-ensembles (des éléments peuvent apparaître plusieurs fois) à la fois dans les hypothèses et les conclusions. Cela nécessite d’introduire une règle explicite dite de contraction qui remplace deux formules égales par une seule. Cela a un impact sur les règles ∀ g et ∃ d dans lesquels les formules ∀ x,P,∃ x,P ne sont pas reportées systématiquement dans les prémisses, l’utilisateur doit explicitement avoir recours à la contraction pour garder la formule quantifiée dans le séquent. Notre formulation garantit que toutes les règles sont inversibles (pas de perte d’information).
Des présentations alternatives du calcul des séquents utilisent plutôt des multi-ensembles (des éléments peuvent apparaître plusieurs fois) à la fois dans les hypothèses et les conclusions. Cela nécessite d’introduire une règle explicite dite de contraction qui remplace deux formules égales par une seule. Cela a un impact sur les règles ∀ g et ∃ d dans lesquels les formules ∀ x,P,∃ x,P ne sont pas reportées systématiquement dans les prémisses, l’utilisateur doit explicitement avoir recours à la contraction pour garder la formule quantifiée dans le séquent. Notre formulation garantit que toutes les règles sont inversibles (pas de perte d’information).
Ce système a de bonnes propriétés pour l’automatisation du raisonnement dans le cas propositionnel. En effet chaque séquent qui apparaît en prémisse d’une règle d’inférence contient moins de connecteurs logiques que celui qui est en conclusion et donc le processus qui consiste à appliquer les règles logiques s’arrête forcément. La profondeur de l’arbre est au maximum égale au nombre de symboles dans le séquent. Nous reviendrons sur ce point dans le chapitre ??
|
Cette règle est correcte, réversible mais elle ne préserve pas la propriété de la sous formule. Un théorème établit que la règle de coupure est redondante :
Preuve: La preuve se fait en transformant les coupures pour faire “diminuer” leur taille. Elle est assez technique puisqu’il faut explorer tous les cas, de plus l’argument de terminaison n’est pas immédiat. Nous donnons ici quelques cas spécifiques.
|
|
|
|
□
Contrairement au cas de la déduction naturelle, il n’est pas nécessaire d’ajouter une règle pour traiter les preuves par l’absurde. Celles-ci se font avec les règles standard mais tirent partie de la présence de plusieurs formules de conclusion et de la possibilité de commencer à décomposer une des conclusions et d’utiliser les éléments collectés pour établir une autre des conclusions.
Ceci est illustré sur la preuve de ⊢ ¬ P∨ P. Après avoir coupé la disjonction en deux conclusions, on commence par essayer de prouver ¬ P, on suppose donc que P est vrai et on devrait établir une contradiction, mais on a aussi la possibilité de s’attaquer à une autre des conclusions, ici P qui permet de conclure.
|
Le calcul des séquents à conséquences multiples nous fournira directement une procédure de décision de la validité pour les formules propositionnelles.
Nous avons construit des systèmes de preuves pour des calculs des séquents. Ces systèmes sont corrects dans le sens ou si Γ ⊢ P alors Γ⊨P. Le théorème de complétude de Gödel nous dit que la réciproque est vraie c’est-à-dire que si une formule est valide alors elle est démontrable dans un système de déduction (la déduction naturelle ou le calcul des séquents sont deux tels systèmes).
Ce théorème reste vrai quand on raisonne dans une théorie donnée. Nous ferons dans le chapitre suivant la preuve pour le cas propositionnel. L’extension pour le calcul des séquents au premier ordre est plus technique (voir par exemple []).
Nous avons présenté deux systèmes de preuve pour raisonner sur des séquents. Il n’est pas très difficile de tranformer les preuves entre ces deux systèmes. On établit les deux résultats suivants :
Dans les deux cas, on raisonne par minimalité de la définition des séquents prouvable dans un système en montrant que chaque règle d’un système peut se dériver dans l’autre système.
Cette partie nous a permis d’introduire la notion de système de preuves pour la logique et la structure de séquents qui généralise la notion de formule et est plus adaptée pour le raisonnement mécanisé. Les techniques de mise en forme clausale seront utiles pour faire des démonstrations par résolution ou pour les méthodes de décision de satisfiabilité. L’automatisation des preuves est le sujet du chapitre 4.