


Dans ce chapitre nous introduisons plusieurs techniques pour automatiser les démonstrations en calcul propositionnel et logique du premier ordre.
Automatiser les démonstrations consiste à trouver un algorithme qui étant donnée une formule quelconque va pouvoir répondre à la question est-ce que cette formule est valide ?
On a vu que ce problème était équivalent à trouver un algorithme qui, pour une formule quelconque, répond à la question est-ce que cette formule est satisfiable ? En effet la validité de la formule A est équivalente à l’insatisfiabilité de la formule ¬ A.
Preuve: Etant donnée une formule de la logique propositionnelle, elle a un nombre fini de variables, n. On peut calculer sa valeur de vérité pour chacune des 2n interprétations et en fonction du résultat, répondre à la question de la validité. □
Evidemment la méthode donnée ci-dessus n’est pas efficace et d’autres techniques existent pour rendre plus effective la procédure. On pourrait se dire que la question de la satisfiabilité d’une formule (problème SAT) est plus simple puisqu’il suffit de trouver une interprétation qui rend vraie la formule. Or ce n’est pas le cas, le problème reste intrinsèquement dur. On rappelle les définitions liées à la NP-complétude dans le cas du problème SAT :
Preuve: La preuve du fait que le problème de satisfiabilité est NP-complet va constituer à ramener la résolution du problème NP à une question de satisfiabilité en logique propositionnelle, en faisant un codage logique de la machine de Turing qui résoud le problème initial. □
On peut chercher des solutions plus efficaces pour des classes particulières de formules.
Si la formule est déjà en forme normale disjonctive, alors la satisfiabilité est immédiate car la formule est soit la formule ⊥ donc insatisfiable soit de la forme C∨ D avec C une conjonction élémentaire et cette conjonction élémentaire a un modèle qui est un modèle de la formule complète. La formule est donc satisfiable. Ce résultat associé au théorème de Cook implique que la complexité de la satisfiabilité se retrouve dans la complexité de mettre une formule quelconque en FND.
On a vu que l’on avait des méthodes linéaires pour ramener la satisfiabilité d’une formule à la satisfiabilité d’une formule en forme normale conjonctive. Cependant, même en se limitant à une formule en FNC dont les clauses propositionnelles ont au plus trois littéraux (problème dit 3-SAT), le problème SAT reste NP-complet.
Contrairement au cas propositionnel, dans le cas de la logique du premier ordre il y a une infinité d’interprétations possibles pour les symboles. On ne peut donc pas les énumérer toutes en général ou construire des tables de vérité.
Dans le cas des formules universelles (avec uniquement des quantificateurs universels en forme prénexe), le théorème de Herbrand nous permet de nous restreindre à une recherche parmi les modèles de Herbrand (interprétation sur le domaine des termes clos). Associé au théorème de compacité, il nous donne une méthode algorithmique pour savoir si une formule P (ou un ensemble de formules) est insatisfiable.
On peut établir les propriétés suivantes de l’algorithme :
On en déduit les résultats suivants :
Preuve: Le premier résultat est une conséquence de l’algorithme présenté ci-dessus et le second en découle en utilisant le fait que tester la validité de A est équivalent à tester l’insatisfiabilité de la formule ¬ A. □
On peut s’interroger sur la possibilité de faire mieux, c’est-à-dire de décider de la validité d’une formule. La réponse est négative.
Preuve: La preuve se fait en ramenant un problème indécidable comme l’arrêt d’une machine de Turing ou la correspondance de Post à un problème de validité en logique du premier ordre. □
On prend comme problème indécidable la correspondance de Post. Soit un ensemble à deux éléments a et b appelés caractères, on appelle mot une suite finie de caractères. On note є le mot vide qui correspond à une suite sans caractères et on note par simple juxtaposition uv, la concaténation de deux mots. On se donne un ensemble fini de couples de mots {(u1,v1);…;(un,vn)}. Une correspondance de Post est une manière d’assembler ces paires de mots en une séquence (non vide) i1,…,ik pour que le mot ui1… uik formé en regardant la première composante soit le même que le mot vi1… vik formé en regardant la seconde composante.
Exemple. Soit le système S =def {(a,baa); (ab,aa); (bba,bb)}.
Avec les notations que précédentes, on pose u1 =def a, v1 =def baa, u2 =def ab, v2 =def aa,u3 =def bba, v3 =def bb. Le mot u3u2u3u1=bba ab bba a est égal au mot v3v2v3v1=bb aa bb baa. On a donc bien une correspondance de Post pour ce système. Par contre si on regarde le système {(ab,aa); (bba,bb)} on montre qu’il n’y a pas de solution : en effet un tel mot solution ne peut pas commencer par (ab,aa) (car cela donne des mots dont la deuxième lettre diffère) ni par (bba,bb) car alors le premier mot sera toujours plus long que le second.
On peut prouver qu’un système particulier a ou n’a pas de solution mais on ne peut pas décider en général (à l’aide d’un programme) si un ensemble de couples de mots {(u1,v1);…;(un,vn)} admet une correspondance de Post.
Nous allons maintenant montrer comment on peut ramener ce problème a un problème logique.
Pour cela on considère un langage avec une constante e pour représenter le mot vide et deux symboles de fonction unaires a et b qui permettent l’ajout de la lettre a ou de la lettre b au début d’un mot. Ainsi le mot baa est représenté dans la logique par le terme b(a(a(e))). Le domaine de Herbrand (ensemble des termes clos) associé à ce langage correspond à l’ensemble des mots sur l’alphabet {a,b} dans le sens où on peut faire correspondre un terme à un mot et réciproquement.
On introduit également un prédicat binaire P et les formules suivantes :
|
On remarque que l’axiome Ai correspond au couple (ui,vi) du problème de Post. On étudie le lien entre une solution au problème de Post et le fait que la formule ∃ x,P(a(x),a(x))∨ P(b(x),b(x)) est conséquence logique de A0, A1, A2, A3.
Pour cela on introduit une relation binaire sur l’ensemble des termes clos : u∼ v si et seulement si il existe k≥ 0 et une séquence i1,…,ik (éventuellement vide) tels que le terme u correspond au mot ui1… uik et le terme v correspond au mot vi1… vik.
La preuve de semi-décidabilité nous a donné un algorithme naïf pour chercher une preuve d’une formule. En effet la méthode énumère au hasard l’ensemble des instances d’une formule et repose à chaque fois la question de la satisfiabilité. Pour améliorer cela, on peut chercher à engendrer des instances qui vont pouvoir interagir avec d’autres parties de la formule pour conduire à une contradiction.
Dans cette section nous explorons plusieurs méthodes pour répondre à la question de la validité ou de la satisfiabilité d’une formule propositionnelle qui ne contient donc pour symboles que des variables propositionnelles et qui ne comporte pas de quantificateur.
Le système G est un calcul des séquents introduit au chapitre précédent (section 3.3.4).
Nous en rappelons les règles dans le cas propositionnel.
On a une règle “hypothèse” (Hyp)
| A,Γ ⊢ Δ,A |
et pour chaque connecteur, une règle gauche et une règle droite rappelées dans le tableau ci-dessous.
|
Ce système a de bonnes propriétés pour l’automatisation du raisonnement. En effet chaque séquent qui apparaît en prémisse d’une règle d’inférence contient moins de connecteurs logiques que celui qui est en conclusion et donc le processus qui consiste à appliquer les règles logiques s’arrête forcément.
On a vu aussi que toutes les règles étaient correctes et inversibles dans le sens qu’une interprétation rend vrai un séquent en conclusion d’une règle si et seulement si elle rend vrais tous les séquents qui apparaissent dans les prémisses.
En particulier, lorsqu’on construit un arbre de dérivation, si un nœud n’est pas valide, alors il existe une interprétation qui rend faux le séquent correspondant et on peut en déduire que la racine de la dérivation est également fausse pour cette interprétation. Et donc le séquent à la racine n’est pas valide. On en déduit une méthode de décision de la validité d’un séquent.
Le séquent Γ ⊢ Δ est valide si et seulement si la règle hypothèse s’applique à chacune des feuilles.
Preuve: Si les feuilles A1,…,An ⊢ B1,…,Bp ne contiennent plus de connecteurs logiques, les formules A1,…,An,B1,…,Bp sont des variables propositionnelles.
Si toutes les feuilles sont des instances de la règle “hypothèse”, l’arbre peut être complété et la conclusion est alors valide.
S’il existe une feuille de l’arbre A1,…,An ⊢ B1,…,Bp qui n’est pas une instance de la règle “hypothèse” alors elle ne contient que des variables propositionnelles distinctes. On peut donc construire une interprétation qui rend vraies les variables Ai et fausses toutes les variables Bj. Comme les règles sont inversibles, le nœud qui est le parent de cette feuille est également faux dans cette interprétation. Et donc la racine de l’arbre qui est le séquent qui nous intéresse est faux dans cette interprétation. Ce séquent n’est pas valide. □
Preuve: Le résultat découle de la propriété 1. On montre la contraposée à savoir que si le séquent n’est pas prouvable alors il n’est pas valide. En effet, en décomposant tous les connecteurs, on peut toujours construire un arbre dont les feuilles sont uniquement composées de variables propositionnelles. Une des feuilles de cet arbre n’est pas une instance de la règle hypothèse (sinon le séquent serait prouvable) et donc par le résultat précédent, le séquent A1,…,An ⊢ B1,…,Bp n’est pas valide. □
Soit la formule ⊢ A ∨ (B ∧ C) ⇒ (A ∨ B) ∧ C. Un arbre de dérivation partiel est :
|
On voit qu’une des feuilles A ⊢ C n’est pas valide et donc on en déduit (sans finir la construction de l’arbre) que le séquent ⊢ A ∨ (B ∧ C) ⇒ (A ∨ B) ∧ C n’est pas prouvable non plus.
Une clause est une disjonction de littéraux et peut se représenter par un ensemble de littéraux. Nous noterons une clause l1∨…∨ ln, chaque littéral apparaitra une seule fois et l’ordre est indifférent.
Le cas où cet ensemble est vide correspond à la proposition ⊥ qui est toujours fausse.
Si la clause contient la formule ⊤ ou contient une variable propositionnelle et sa négation, elle est toujours vraie (clause triviale). Nous nous intéressons à la satisfiabilité d’un ensemble de clauses, et une clause toujours vraie est satisfiable dans toutes les interprétations. Une clause triviale peut donc être retirée de l’ensemble considéré sans changer le problème (E est satisfiable si et seulement si E∪{⊤} est satisfiable). Une clause non triviale peut donc toujours se représenter par un ensemble de littéraux qui sont soit des variables propositionnelles soit des négations de variables propositionnelles et la même variable n’apparaît pas deux fois.
On suppose donné un ensemble de clauses E. On cherche à savoir si ces clauses sont satisfiables, c’est-à-dire s’il existe une interprétation I telle que I⊨ E. La notation I⊨ E représente le fait que pour toute formule P∈ E, on a I⊨ P.
Pour cela on va se donner un système de règles qui nous permet de dériver de nouvelles clauses C telle que si I⊨ E alors on a aussi I⊨ C. Le but du jeu est d’aboutir à la clause vide qui représente ⊥ et qui est insatisfiable et donc d’en conclure que l’ensemble de clauses initial n’est pas satisfiable (il n’existe pas d’interprétation I telle que I⊨ E).
|
Soit E un ensemble de clauses, une déduction par résolution à partir de E est une suite de clauses C1,…,Cn telle que pour toute clause Ci dans cette suite soit Ci∈E, soit il existe deux clauses Cj et Ck telles que j,k< i et telle que Ci soit le résultat de la règle de résolution appliquée à Cj et Ck.
C’est-à-dire que
| Cj Ck |
| Ci |
est un cas particulier de
| C ∨ ¬ p C′∨ p |
| C∨ C′ |
De manière équivalente, l’ensemble des clauses déductibles par résolution à partir d’une ensemble de clauses E est le plus petit ensemble qui contient les clauses de E et qui satisfait la condition associée à la règle de résolution vue comme une règle d’inférence.
|
| ¬ p ∨ ¬ q ∨ r, p, ¬ q ∨ r, ¬ r,¬ q |
|
| ¬ (¬ (p ∨ (q ∧ r)) ⇒ (¬ q ∨ ¬ r)) ≡ ¬ (p ∨ (q ∧ r)) ∧ (q ∧ r) ≡ ¬ p ∧ (¬ q ∨ ¬ r) ∧ q ∧ r |
|
Preuve:
La minimalité nous donne que I⊨ C2∨ ¬ p et I⊨ C1∨ p. On raisonne par cas suivant la valeur de la variable p dans l’interprétation I. Si p est vrai alors ¬ p est faux et donc I⊨ C2 et si p est faux alors I⊨ C1. Dans les deux cas, on a bien I⊨ C1∨ C2, c’est-à-dire I⊨ C.
□
On peut se poser la question de savoir si la méthode de résolution peut toujours nous donner la solution. C’est-à-dire si on se donne un ensemble E de clauses insatisfiable, est-ce qu’il existe une réfutation de E par la méthode de résolution. La réponse est oui.
Preuve: On va faire la preuve dans le cas où d’un nombre fini ou dénombrable de variables propositionnelles (pi)i∈ℕ.
On construit un arbre binaire de décision. Chaque niveau est étiqueté par une variable propositionnelle, en partant de p0, le sous-arbre gauche correspond au cas où cette variable vaut V et le sous-arbre droit, au cas où elle vaut F. Chaque branche (possiblement infinie) correspond donc à une interprétation logique des variables propositionnelles (pi)i∈ℕ.
Si on a juste deux variables p et q, l’arbre de décision se présentera ainsi (on a indiqué pour chaque sommet l’interprétation correspondante)
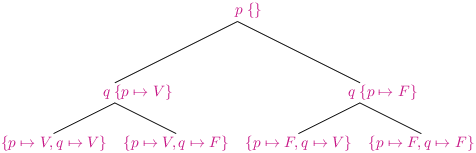
Chaque nœud interne de l’arbre correspond à une interprétation partielle des variables. Au niveau de la racine, aucune variable n’a de valeur.
Si l’ensemble E est insatisfiable alors pour chaque interprétation I, il existe une clause C∈E telle que I⊭C. Comme C n’a qu’un nombre fini de variables, on peut positionner la formule dans l’arbre le plus haut possible telle que l’interprétation I restreinte à p0,…,pn rend faux la clause C. Il est possible de faire cela pour toutes les branches de l’arbre. On va appeler un tel arbre un arbre de réfutation de E.
Par exemple un arbre de réfutation pour l’ensemble de clauses {p ∨ q , p ∨ ¬ q, ¬ p} est :
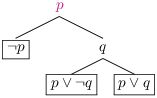
Un arbre à branchement fini dont toutes les branches sont finies est lui-même fini (lemme de König). Donc on a un arbre fini, et chaque feuille contient une clause de E qui est fausse dans l’interprétation correspondant à la branche. Soit un arbre de réfuytation pour un ensemble E de clauses insatisfiable. Il se peut que cet arbre soit réduit à une feuille, celle-ci doit correspondre à une formule qui est fausse dans l’interprétation vide, il ne peut s’agir que de ⊥ et donc ⊥∈ E et on a une réfutation triviale par résolution.
Si l’arbre n’est pas vide, on a un nœud de la forme
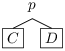 avec p une variable propositionnelle et C et D des clauses. Soit I l’interprétation des variables autres que p qui correspond au chemin de la racine de l’arbre jusqu’à p. Attention I ne définit pas la valeur de toutes les variables propositionnelles, c’est seulement une interprétation partielle et donc toutes les clauses ne peuvent pas être évaluées dans cette interprétation.
avec p une variable propositionnelle et C et D des clauses. Soit I l’interprétation des variables autres que p qui correspond au chemin de la racine de l’arbre jusqu’à p. Attention I ne définit pas la valeur de toutes les variables propositionnelles, c’est seulement une interprétation partielle et donc toutes les clauses ne peuvent pas être évaluées dans cette interprétation.
On a I,{p↦ V}⊭C et I,{p↦ F}⊭D par définition des arbres de réfutation. La variable propositionnelle p apparait dans C et dans D (sinon on aurait pu faire remonter l’une de ces clauses plus haut dans l’arbre). On a forcément C=C′∨ ¬ p et D=D′∨ p (sinon les clauses seraient vraies à l’endroit où elles sont positionnées). Ce qui signifie que l’on peut faire une étape de résolution entre les deux clauses, qui nous donnera une clause C′∨ D′ telle que I ⊭C′∨ D′. On peut donc remplacer le sous arbre [.p C D ] par la clause C′∨ D′.
On voit donc qu’au fur et à mesure que l’on construit la déduction par résolution, on a un ensemble de clauses pour lequel l’arbre de réfutation diminue. Au final on aura un arbre réduit à une feuille ⊥ ce qui correspond à une réfutation. □
Evidemment cette démonstration n’est pas une manière effective de guider la recherche d’une réfutation par la méthode de résolution puisque si on avait l’arbre de réfutation on pourrait conclure immédiatement que l’ensemble de clauses est insatisfiable sans avoir recours à la résolution. Il faut parfois une peu d’intuition pour aboutir à la clause vide. Suivant la forme des clauses on peut avoir des stratégies plus précises.
Il se peut qu’en faisant une étape de résolution on trouve la clause triviale ⊤ ou que l’on retombe sur une clause déjà connue. Cela ne signifie pas forcément que l’on s’est trompé ou que l’ensemble de clauses est satisfiable mais juste que les étapes de calcul faites étaient inutiles. Il faut alors chercher d’autres combinaisons ou s’interroger si l’ensemble de clauses de départ est bien insatisfiable.
Il existe des méthodes qui, au lieu de chercher une contradiction dans un ensemble de clauses, vont au contraire chercher à construire une interprétation qui satisfait l’ensemble des clauses en collectant les contraintes sur les variables induites par ces clauses.
La procédure DPLL (du nom de ses inventeurs Davis, Putnam, Logemann et Loveland) permet de dire si une formule en forme normale conjonctive (représentée par un ensemble de clauses) est satisfiable. Pour cela, l’algorithme cherche à construire une interprétation qui rend la formule vraie.
L’algorithme DPLL travaille sur des problèmes de la forme : I ≫ Δ avec I une interprétation partielle des variables propositionnelles de la forme {x1↦ b1;…;xn↦ bn} (que l’on peut aussi représenter comme un ensemble de littéraux xi si bi=V et ¬ xi si bi=F)
et Δ un ensemble de clauses C1,…,Cn. On note Δ,C le problème qui contient toutes les clauses de Δ plus la clause C.
Le but de l’algorithme est de construire une interprétation qui étend I, c’est-à-dire de la forme {x1↦ b1;…;xn↦ bn;xn+1↦ bn+1… xp↦ bp} et qui rend vraies toutes les clause Ci.
Les règles sont les suivantes :
Il y a deux cas triviaux. Le premier cas s’il n’y a plus de clauses, l’interprétation I répond au problème. Le second cas si l’une des clauses Ci est la clause vide alors le problème n’a pas de solution. Cela correspond aux deux règles :
| Success |
| Conflict |
|
Par ailleurs on peut simplifier les problèmes : lorsque l’interprétation I fixe la valeur de la variable x, alors les clauses C qui contiennent un litteral l de la forme x ou ¬ x se simplifient :
Ceci est représenté par les deux règles suivantes :
| BcpV |
| BcpF |
|
Maintenant si aucune des règles précédentes ne s’applique, alors il faut préciser l’interprétation en choisissant une valeur pour une nouvelle variable. Un cas simple est si une clause ne contient qu’un seul littéral alors pour que la clause soit vraie il faut choisir la valeur de la variable pour rendre ce littéral vrai. Ceci s’exprime par les règles suivantes :
| AssumeV |
| AssumeF |
|
Si maintenant, il n’y a aucune clause réduite à un littéral, alors il n’y a pas de choix évident. On va donc choisir une variable qui n’a pas encore de valeur et explorer les deux branches : celle où cette variable est interprétée par V et celle où elle est interprétée par F.
| Unsat |
|
On part d’un ensemble de clauses Δ et d’une interprétation vide. On construit un arbre en utilisant les règles précédentes et on cherche à arriver à une feuille de succès de la forme I≫∅. L’interprétation I est une solution de notre problème, elle rend vraies l’ensemble des clauses Δ.
Si toutes les feuilles de l’arbre correspondent à des conflits alors l’ensemble de clauses initial n’est pas satisfiable.
On a vu que la question de la satisfiabilité nécessitait de produire des instances de formules, c’est-à-dire de remplacer des variables par des termes ayant de bonnes propriétés. Dans cette section, nous allons introduire un outil, l’unification, qui nous sera utile dans la méthode de résolution pour produire des instances particulières de formules. L’unification traite une classe de problèmes très simples à savoir des équations entre termes avec variables. C’est un problème qui a des applications multiples comme la question de l’inférence de types dans les langages fonctionnels.
L’unification est également l’ingrédient majeur des systèmes de réécritures qui sont des théories logiques dans lesquelles le seul symbole de prédicat est celui de l’égalité et les axiomes en plus de ceux de l’égalité sont de la ∀(t=u) de tels systèmes sont à la fois utilisés pour le raisonnement et comme langage de programmation.
On se donne une signature F pour les termes et un ensemble X de variables. On rappelle qu’une substitution est une application σ ∈ X→ T(F,X). On s’intéresse à des substitutions dites à support fini c’est-à-dire telles que σ(x)=x sauf pour un nombre fini de variables. De telles substitutions se représentent facilement comme des ensembles finis {x← σ(x) | x∈ X ∧ σ(x)≠x}. Ainsi, la substitution identité telle que σ(x)=x pour tout x∈ X se représentera simplement par un ensemble vide {}.
Étant donnée une substitution, on a défini dans la section 1.5.3 une application de T(F,X)→ T(F,X) qui à un terme t associe le terme noté t[σ] dans lequel on a remplacé chaque variable x par σ(x).
 D’un point de vue fonctionnel, la notation σ1σ2 correspond à appliquer la substitution σ1 suivie de σ2, ce qui d’un point de vue mathématiques correspond à la composition de fonctions σ2∘σ1
D’un point de vue fonctionnel, la notation σ1σ2 correspond à appliquer la substitution σ1 suivie de σ2, ce qui d’un point de vue mathématiques correspond à la composition de fonctions σ2∘σ1
Il ne faut pas confondre la composition de deux substitutions qui correspond à deux substitutions successives avec la substitution simultanée. Ainsi si on pose σ1={x← y} et σ2={y← z}. On a σ1σ2={x← z;y← z} et (x+y)[σ1σ2]=z+z alors que la substitution simultanée est définie par {x← y;y← z} et donne le résultat (x+y)[x← y;y← z]=y+z.
De manière plus générale, on peut se donner un ensemble de couples de termes {(ti,ui)|i∈ I}. Résoudre ce problème d’unification revient à chercher une substitution σ telle que ti[σ]=ui[σ] pour tout i∈ I.
Il s’agit de la résolution d’une équation (ou d’un système d’équations), on trouve des valeurs pour les variables qui apparaissent dans t et u, telles que si on remplace les variables par ces valeurs, alors les deux termes obtenus sont syntaxiquement égaux. On rappelle que les termes f(t1,…,tn) et g(u1,…,up) sont (syntaxiquement) égaux uniquement lorsque les symboles f et g sont égaux, on a alors la même arité donc p=n et on doit avoir récursivement ti=ui pour i=1… n.
Si σ1 est une solution du problème d’unification t=? u alors il en est de même de σ1σ2 pour toute substitution σ2. En effet on a t[σ1]=u[σ1] car σ1 est solution du problème et donc t[σ1σ2]=t[σ1][σ2]=u[σ1][σ2]=u[σ1σ2].
Si on a deux solutions σ et τ a notre problème d’unification, on dira que σ est plus générale que τ s’il existe une substitution σ′ telle que σσ′=τ.
Une bonne propriété de l’unification sur les termes syntaxiques est que si un problème a une solution alors il existe une solution qui est plus générale que toutes les autres. Et donc pour calculer l’ensemble de toutes les solutions, il suffit de calculer cette substitution que l’on appelle aussi unificateur principal.
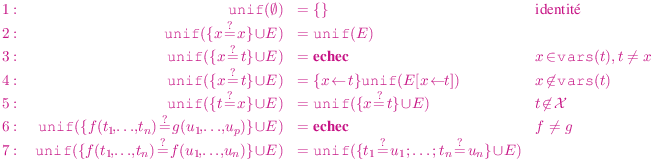
Preuve: On vérifie que chaque cas possible pour l’ensemble E est couvert par une équation unique : l’ensemble est soit vide soit il contient une équation et cette équation a son terme gauche qui est ou non une variable et si le terme gauche n’est pas une variable on regarde le cas où le terme droit est ou non une variable.
Un problème plus délicat à justifier est la terminaison de cette définition vue comme un procédé de calcul. Dans les cas récursifs, on regarde ce qui diminue :
En résumé pour un problème E si on regarde le triplet nbvars(E),taille(E),nbeqs(E) avec nbvars(E) le nombre de variables différentes dans E, taille(E) le nombre d’occurrences de symboles dans E, et nbeqs(E) le nombre d’équations dans E, alors on remarque que chaque appel se fait sur un problème strictement plus petit si on prend l’ordre lexicographique, sauf celui où on change l’équation t=x en x=t. Mais cette règle n’est appliquée que lorsque t n’est pas une variable et sera donc immédiatement suivie de l’application d’une règle qui fait diminuer le “poids” du problème. Une autre possibilité est de définir taille(t=? u) =def 2× nbsymb(t)+nbsymb(u) au lieu de taille(t=? u) =def nbsymb(t)+nbsymb(u). On a alors taille(x=? t)<taille(t =? x) lorsque t n’est pas une variable.
On vérifie que les cas d’échec correspondent à des problèmes sans solution et que dans les cas où une solution est trouvée, il s’agit bien de l’unificateur principal. □
L’algorithme de Robinson est naturel mais n’est pas efficace à cause en particulier de l’opération de substitution lorsqu’on élimine l’équation x=? t. On peut utiliser une représentation des termes qui rend cette opération moins coûteuse. Il existe d’autres algorithmes plus complexes mais plus efficaces.
L’unification est une opération utilisée dans de nombreuses applications, par exemple dans l’algorithme de typage des programmes Ocaml afin de trouver le type le plus général que peut traiter une fonction. L’unification se généralise également à des théories plus complexes dans lesquelles l’égalité entre termes n’est plus syntaxique mais prend en compte des propriétés des opérations comme la commutativité ou l’associativité. Suivant les théories, on va perdre la décidabilité ou l’existence d’un unificateur principal.
L’unification sur les termes se généralise en une unification entre des littéraux. Si on a deux littéraux P et Q, ils s’unifient s’il existe une substitution σ telle que P[σ]=Q[σ]. Si P est de la forme R(t1,…,tn) (resp. ¬ R(t1,…,tn)) alors σ est un unificateur de P et Q si et seulement si Q est de la forme R(u1,…,un) (resp. ¬ R(u1,…,un)) et σ est un unificateur de l’ensemble de problèmes {ti=? ui|i=1… n}.
| t≤ u |
| il existe σ tel que u=t[σ] |
Si u=t[σ], on dit que t est plus général que u et que u est une instance de t.
Un terme avec variables t∈T(F,X) représente un ensemble de termes clos (sans variables), les instances closes de t:
| inst(t) |
| {u∈T(F)|il existe σ tel que u=t[σ]} |
Preuve: Si t≤ u alors u=t[σ] et toute instance close de u est de la forme u[τ]=t[σ][τ]=t[στ] et est donc une instance close de t. □
Le langage Ocaml permet de définir une expression par cas suivant un ensemble de motifs
A l’exécution, e a pour valeur un terme clos (v)
On peut analyser les motifs
On s’intéresse ici au problème de savoir si un ensemble de formules de la logique du premier ordre est satisfiable ou non, c’est-à-dire s’il existe une interprétation qui rend vraies simultanément toutes les formules. On rappelle qu’un ensemble fini de formules est satisfiable si et seulement si la conjonction de toutes les formules est elle-même une formule satisfiable. On a vu au chapitre 3 que l’on pouvait se ramener au cas où les formules manipulées sont uniquement des clauses (disjonction de littéraux), universellement quantifiées dans le cas de la logique du premier ordre.
La technique de preuve par résolution est importante car elle est à la base non seulement de systèmes de démonstration automatique mais aussi de systèmes de programmation logique. Le plus connu est le langage de programmation Prolog, dans lequel le programme est modélisé comme un ensemble de clauses et un calcul se fait par la recherche d’une preuve.
Nous avons traité le cas de la résolution en logique propositionnelle, nous voyons ici comment la méthode se généralise en logique du premier ordre.
En logique propositionnelle, une clause est un ensemble de littéraux (variable propositionnelle ou négation de variable propositionnelle) et on se ramène au cas où chaque variable propositionnelle apparaît une seule fois.
Dans le cas du premier ordre, les littéraux sont de la forme R(t1,…,tn) ou ¬ R(t1,…,tn) avec R un symble de prédicat et ti des termes. Le même symboles peut donc apparaître plusieurs fois dans la clause de manière positive ou négative associée à des termes différents.
Par ailleurs les termes qui apparaissent dans les clauses peuvent contenir des variables. De fait une clause C qui contient les variables {x1,…,xn} est juste une représentation sans quantificateur de la formule ∀ (C) (notation pour ∀ x1 … xn,C).
Une autre interprétation de la clause avec variables C est l’ensemble des instances closes (sans variable) de la formule c’est-à-dire l’ensemble des clauses C[σ0] avec σ0 une substitution qui remplace chaque variable de C par un terme clos. Le théorème de Herbrand nous a permis d’établir que la satisfiabilite de la formule ∀ (C) était équivalente à la satisfiabilité de l’ensemble (potentiellement infini) de toutes les instances closes de C. C’est ce qui est exploité dans la résolution au premier ordre.
On part d’un ensemble de clauses (disjonction de littéraux vue comme un ensemble de littéraux). On rappelle que l’unification sur les termes s’étend de manière naturelle à l’unification sur les littéraux. Deux littéraux L1 et L2 s’unifient s’ils sont de la forme R(t1,…,tn) et R(u1,…,un) ou bien ¬ R(t1,…,tn) et ¬ R(u1,…,un) et que le problème (ti=? ui)i=1… n admet une solution. Dans ce cas on note unif(L1,L2) l’unificateur principal.
|
|
|
| C∈E |
| C |
Les définitions de réfutation par résolution et de preuve par résolution sont les mêmes que dans le cas propositionnel (définition 2) mais avec la notion de déduction par résolution générale.
On construit la déduction par résolution (on indique pour chaque règle la substitution qui est utilisée)
|
La règle de renommage sert juste à préparer les clauses pour appliquer la règle de résolution dont une des conditions est que les deux clauses ne partagent pas de variable.
La règle de factorisation permet de faire disparaitre plusieurs littéraux lors d’une étape de résolution binaire. Elle est indispensable comme l’illustre l’exemple ci-dessous.
Ces deux règles sont triviales dans le cas propositionnel. La règle de résolution générale généralise la règle de résolution propositionnelle.
|
Par contre, on peut commencer par effectuer des factorisations sur les deux clauses dont on déduit facilement une contradiction
|
On commence par mettre ¬ A en forme clausale.
On procède ensuite aux étapes de résolution en vue de produire la clause vide :
|
On conclut : ¬ A est insatisfiable donc A est valide.
La correction de la méthode de résolution établit que si l’on peut déduire une clause C à partir d’un ensemble de clauses E alors la formule ∀(C) est conséquence logique de l’ensemble des formules {∀ (D)|D ∈ E}.
On commence par établir quelques propriétés simples qui relient entre elles les clauses généralisées et leurs instances. Soient A et B deux formules, x une variable et t un terme.
Ces résultats se généralisent au cas de plusieurs formules et plusieurs variables. Si σ est une substitution alors ∀ (C) ⊨ C[σ] qui se déduit du lien entre substitution et vérité :
| val(ρ,C[σ])=val({x↦ val(ρ,σ(x))|x∈Vl(C)},C) |
Par ailleurs si E est un ensemble de formules, si E ⊨ B et si les variables libres de B ne sont pas libres dans les formules de E, alors E ⊨ ∀ (B).
En particulier s’il existe une réfutation de E, alors {∀ (D)|D ∈ E}⊨ ⊥ et donc {∀ (D)|D ∈ E} est insatisfiable.
Preuve: On va montrer la correction de chacune des règles en montrant que la généralisation de la conclusion (clause sous la barre) est une conséquence logique de la généralisation des hypothèses (clause(s) au-dessus de la barre):
|
| C |
| C[σ] |
|
□
La méthode de résolution est aussi complète dans le cas de la logique du premier ordre, c’est-à-dire que si E est un ensemble de clauses et que ⊥ est une conséquence logique de {∀(C)|C ∈ E} alors on peut déduire la clause vide par la méthode de résolution à partir de l’ensemble E.
Ce résultat utilise le Théorème de Herbrand et la compacité qui nous permettent d’établir qu’il existe un ensemble fini insatisfiable d’instances closes des clauses de E :
| F={C1[σ1],…,Cn[σn]} |
.
L’ensemble F est propositionnel, on peut donc par le théorème de complétude de la résolution propositionelle construire une réfutation par résolution de cet ensemble.
La clé de la preuve est ensuite le Lemme de relèvement qui permet d’établir que les étapes faites au niveau de la déduction propositionnelle peuvent se simuler au travers des règles de résolution au premier ordre.
|
Nous ne détaillerons pas la preuve ici. On pourra regarder plus précisément les points suivants.
La méthode de résolution consiste à combiner des clauses dans le but d’obtenir la clause vide. Néanmoins il y a de nombreuses manières différentes de la faire et on peut s’interroger s’il existe des stratégies plus efficaces que d’autres.
Supposons qu’un des symboles de prédicat R n’apparaisse que de manière positive dans les clauses. Alors toutes les clauses dans lesquelles ce symbole apparaît peuvent être éliminées.
Le même résultat s’applique si le symbole R n’apparait que de manière négative dans les clauses.
Il arrive que dans une dérivation, on puisse retomber sur une clause qui ressemble à une clause déjà rencontrée. Supposons qu’on ait à la fois une clause C et une clause C[σ]∨ D, alors la clause C[σ]∨ D peut être ignorée. En effet on a ∀(C)⊨ ∀ (C[σ]∨ D) donc E,∀(C),∀ (C[σ]∨ D)⊨ ⊥ si et seulement si E,∀(C)⊨ ⊥
Lorsque l’on combine deux clauses par la méthode de résolution, on peut obtenir en général une clause qui est aussi grosse voir plus grosse que les clauses dont on est parti. Sauf si une des deux clauses est composée d’un seul litteral (on dit que la clause est unitaire) auquel cas la clause obtenue après résolution est plus petite que la clause dont on était parti.
Malheureusement, la stratégie de choisir de faire toujours une résolution avec une clause réduite à un littéral ne fonctionne pas. En effet il y a des ensembles de clauses contradicatoires qui ne contiennent pas de clause unitaire et la stratégie de choisir toujours une clause unitaire peut nous amener à ne jamais considérer ces clauses. C’est ce qui se passe dans l’exemple suivant :
| {P(a),¬ P(x)∨ P(f(x)),¬ p ∨ ¬ q,¬ p ∨ q, p ∨ ¬ q,p∨ q} |
La stratégie unitaire engendre un ensemble infini de clauses {P(f(a)),P(f(f(a))),…,P(fn(a)),…} qui ne mêne pas à une contradiction alors que l’ensemble {¬ p ∨ ¬ q,¬ p ∨ q, p ∨ ¬ q,p∨ q} est lui insatisfiable (comme montré dans l’exercice 3).
Les clauses de Horn sont des cas particuliers de clauses qui contiennent au plus un seul littéral positif (sans négation). Les règles de la résolution appliquées à des clauses de Horn produisent des clauses de Horn.
L’intérêt des clauses de Horn réside dans le résultat suivant.
Preuve: La preuve suit les étapes suivantes
|
|
□
En 1972, l’informaticien Alain Colmerauer qui s’intéressait au traitement automatique des langues introduit, avec Philippe Roussel, le langage ProLog.
Le principe de base est de modéliser un problème à l’aide de Clauses de Horn.
Une clause avec un littéral positif p : ¬ p1∨ … ∨ ¬ pn∨ p est écrite sous la forme p:- p1,…, pn. et peut se lire comme (p1∧ … ∧ pn) ⇒ p qui est bien équivalent à ¬ p1∨ … ∨ ¬ pn∨ p
Lorsque la clause ne contient pas de littéral positif, elle s’écrira sous la forme :- p1,…, pn. et peut se lire comme (p1∧ … ∧ pn) ⇒ ⊥ qui est bien équivalent à ¬ p1∨ … ∨ ¬ pn ≡ ¬(p1∧ … ∧ pn).
Lorsque la clause est composée uniquement d’un littéral positif p, elle s’écrit simplement p.
Pour exécuter un programme, on va poser des questions sous la forme d’une conjonction de littéraux positifs qui peuvent contenir des variables.
Le système va rechercher les instances de ce programme qui sont conséquence logique des clauses du programme. Pour cela il va utiliser la méthode de résolution pour rechercher des contradictions à partir de la négation de ces prédicats.
Si maintenant la question est de chercher toutes les personnes dans la fratrie de sally, cela se traduit par :
il s’agit de trouver pour quelles valeurs de x ce problème a une solution. Les étapes vont être analogues
La clause 10 se combine alors avec la question 6 pour obtenir la clause vide au travers de la substitution x← erica qui est renvoyée à l’utilisateur.
Ce langage a des applications en intelligence artificielle, linguistique, bases de données, etc.
Un important aspect est la possibilité de retour en arrière (back-tracking) après avoir trouvé une solution pour énumérer l’ensemble des instances possibles solutions du problème.
Nous avons vu que le système G avait des bonnes propriétés dans le cas propositionnel. Au premier ordre, les règles ∀ g et ∃ d nécessitent de trouver le bon terme à appliquer et il peut aussi être nécessaire de les appliquer plus d’une fois sans que l’on puisse a priori borner cette recherche.
Le calcul des séquents est la base théorique des méthodes de démonstration automatique appelées méthodes des tableaux.
Le principal ingrédient est d’ajouter au langage des termes une nouvelle sorte de variables, les inconnues qui seront utilisées lors de l’application des règles ∀ g et ∃ d à la place du terme t à “deviner”. On décompose tous les connecteurs pour chercher des solutions au niveau des feuilles afin de pouvoir appliquer la règle axiome. Là encore c’est l’unification qui va nous permettre de trouver des solutions pour nos inconnues.
Les règles modifiées sont les suivantes, au lieu d’un terme quelconque, t nous remplaçons la variable liée par une “inconnue X :
| (∀′ g) |
| (∃′ d) |
|
Un arbre de dérivation qui contient des inconnues ne constitue pas une preuve. Il sera souvent incomplet car les inconnus peuvent empécher l’application de la règle hypothèse aux feuilles.
|
Pour que l’arbre puisse être complété par une règle hypothèse, on voit qu’il faut appliquer la substitution {X← x,Y← y}
Une difficulté supplémentaire est que les règles droites pour le ∀ et gauche pour le ∃ ont des conditions sur les noms des variables ordinaires de termes; et que cela ajoute des contraintes sur les solutions pour les inconnues. Il faut donc vérifier que les solutions trouvées par l’unification respectent ces conditions. C’est le cas de l’exemple précédent, les règles ∃ g (1) qui introduit y et ∀ d (2) qui introduit x sont utilisées avant l’introduction d’inconnues et respectent la condition que les variables introduites ne sont pas utilisées ailleurs.
Si maintenant on essaie avec la même méthode de faire une preuve de la propriété réciproque.
|
Il est tentant de compléter la preuve comme précédemment en appliquant la substitution {X← x,Y← y}. Cependant cela nous donnerait l’arbre suivant (pour ne pas alourdir l’arbre, on a retiré les formules dupliquées dans les règles ∃ d et ∀ g)
|
L’arbre n’a plus de feuilles mais ne constitue pas néanmoins un arbre de preuve (le séquent est d’ailleurs non valide). En effet la condition que y est une variable non utilisée dans la règle ∃ g (1) n’est pas vérifiée puisque y est libre dans la conclusion ∀ x, R(x,y) et de même la condition de la règle ∀ d (2) qui impose que x n’est pas utilisé par ailleurs n’est pas respectée puisque x est libre dans l’hypothèse R(x,y). On voit donc que l’utilisation des règles ∃ g et ∀ d va imposer des restrictions sur les variables qui peuvent être utilisées pour les valeurs des inconnues. Ces conditions devront être vérifiées globalement lorsqu’on cherche les solutions pour compléter les feuilles par des règles hypothèses.
Une théorie est un ensemble (fini ou infini) de formules closes. Une théorie peut se voir comme un ensemble de contraintes sur les symboles de la signature. Des exemples sont la théorie des ensembles, fondement des mathématiques modernes, l’arithmétique de Peano, cadre logique plus restreint mais qui permet de parler des fonctions calculables ou encore dans le cadre informatique des théories correspondant à des structures de données comme la théorie des piles.
Soit A une théorie, on s’intéresse aux formules qui sont vraies dans une théorie A, c’est-à-dire que toute interprétation qui satisfait les axiomes de la théorie, satisfait la formule P, ce qui est noté A⊨ P. La calcul des prédicats est indécidable en général mais certaines théories sont décidables.
Soit une théorie A
Beaucoup de théories sont incomplètes
Preuve: Les preuves de A⊢ P peuvent être énumérées car la théorie est récursive et l’ensemble des symboles est dénombrable. On cherche en parallèle des preuves de A⊢ P et de A⊢ ¬ P, l’un des deux va aboutir. □
Il n’y a pas de théorie “universelle” (ex. théorie des ensembles) qui permette de montrer soit A soit ¬ A, pour toute formule.